참고로 팁을 하나 써 놓자면, 한국 IP로 위 링크에 접속했을 때는 한국어 페이지(https://learn.microsoft.com/ko-kr)로 리디렉션된다. 여기는 MS 영문 페이지를 한국어로 번역해 놓은 건데, 대체로 부드럽지만 가끔 알아먹기 힘들 때가 있다. (mapping data flows 기능을 '매핑 데이터 흐름'이라고 한다거나, Detect를 탐지가 아닌 검색으로 번역하기도 한다.) 따라서 공부할 때 영문 페이지(https://learn.microsoft.com/en-us/)를 같이 쓰는 것을 추천한다.
(중간 추가) 그냥 영어 페이지는 필수다. 단적으로, 이런 번역도 존재한다. Missing value imputation to eliminate nulls in the training dataset -> 제대로 된 번역은 'null값 제거를 위해 누락된 값 처리'겠지만, 이를 'null 값을 제거하기 위한 값 처리 누락'이라고 해 놨다(...)
기계 학습 솔루션 설계 단원은 크게 네 개의 소단원으로 나뉜다.
(1) 데이터 수집 전략 설계
(2) 학습 솔루션 설계
(3) 모델 배포 솔루션 설계
(4) ML Operation 설계
하나씩 가보자.
데이터 수집 전략 설계
<학습 목표> 데이터 원본 및 형식 식별을 할 수 있다. ML workflow에 데이터를 import 할 수 있다. 데이터 수집을 디자인할 수 있다.
1. 데이터 원본 및 형식 식별
모델링의 6단계는 다음과 같다.
문제 정의 - 데이터 가져오기 - 데이터 준비 - 모델 학습 - 모델 통합 - 모델 모니터링
영어를 우리말로 번역해 놓은거라 잘 안 와 닿는다.
문제 정의 : 모델의 예측 대상과 기준 설정
데이터 가져오기 : 데이터에 접근하고 로드
데이터 준비 : EDA
모델 학습 : 모델을 학습시키며 하이퍼파라미터 조정
모델 통합 : 엔드포인트에 모델을 배포(model.pred()를 말한다.)
모델 모니터링 : 성능 확인, 시각화, 추적
이 과정에 앞선 것이 데이터 원본 및 형식 식별이다.
<데이터 원본 식별>
문과인 입장에서는 표현이 좀 이상한데, 데이터의 출처를 식별하는 것이다. (source가 원본으로 번역된듯?)
그 종류는 다음과 같다.
- 기존 시스템에 저장된 데이터 : CRMS(고객 자원 관리 시스템), SQL 데이터베이스 - IoT 디바이스에서 생성되는 데이터 : 내비 위치 데이터, 스마트폰 운동 데이터 등 - 공공 데이터 - 이외의 데이터 수집 프로세스로 인해 수집된 데이터
<데이터 수집 / 모델 학습에 쓰는 서비스> Azure Machine Learning Azure Databricks Azure Synapse Analytics (얘네들은 밑에서 다시 보자.)
<데이터 저장에 쓰는 서비스> Azure Blob : 기본 스토리지. 비정형 데이터 Azure Data Lake(Gen 2) : 대용량 스토리지, 비정형 데이터, 계층적 액세스 권한 관리 Azure SQL DataBase : 정형 데이터, 데이터와 스키마 이원적 구조
3. 데이터 수집 솔루션 설계
데이터 수집 솔루션 = 데이터 수집 파이프라인이다.
이 과정에서, 위에 말했던 ML 서비스들이 쓰인다.
<Azure Synapse Analytics>
Azure에서 미는 가장 정석적인 데이터 수집 도구
Azure Synapse Analytics에 있는 기능 중,
Synapse Pipelines를 활용한다.
코딩 없이 쉬운 UI가 특징이며, JSON 형식으로 파이프라인을 정의한다.
파이프라인에 대해 '표준 커넥터'를 사용함으로써, 스토리지로 복사하기가 용이하다.
수집 파이프라인의 끝에 데이터 변환 작업을 추가할 수 있는데,
이때는 Azure Data Factory의 노코딩 UI 툴 중 하나인
mapping data flows를 쓰거나, 파이썬 / SQL / R 등 데이터 분석에 쓰이는 언어로 처리하면 된다.
이 데이터 수집/변환 과정에 필요한 자원도 제공하는데,
서버리스 SQL pool, 전용 SQL pool, Spark pool 중에 선택하면 된다.
서버리스 SQL 풀 : 서버리스답게 요청 시에만 실행된다. 전용 SQL 풀과 비교하면 소규모 데이터를 처리한다. 전용 SQL 풀 : 고정된 리소스를 제공하여 데이터 웨어하우스와 같은 환경을 구성해 둔다. Spark 풀 : SQL이 아닌 언어(파이썬 / R / .NET 등)도 지원한다. 주로 머신러닝에 쓰인다.
<Azure Databricks>
노코딩 툴인 Synapse Analytics와는 달리, 코딩 기반의 도구다.
SQL / 파이썬 / R을 지원한다.
내게 익숙한 방식인,
notebook 환경 파이프라인을 정의를 쓰는 셈.
Synapse Analytics는 다양한 자원을 사용했으나,
SQL 외의 언어도 지원하는 Databricks는 당연히 Spark 기반의 자원을 쓴다.
<Spark> 위에서 반복 등장하는 스파크는, 정확히 말하자면 Apache Spark 클러스터를 말한다.
Apache Spark는 오픈 소스 기반의 빅데이터 분석 플랫폼으로, 메모리 기반의 분산 처리를 제공하는 녀석이다.
이것을 통한 작업은 분산 컴퓨팅이기 때문에, 여러 서버를 조합한 하나의 클러스터를 필요로 한다.
그게 위에서 말하는 Apache Spark 클러스터. Azure 서비스의 일부 기능으로 Spark가 들어간 녀석들은 다 이 방식을 사용한다고 보면 된다.
<Azure Machine Learning>
이름처럼 ML에 자주 쓰이는 서비스이다.
하지만 ML과 데이터 처리는 불가분의 관계인지라
당연히 이녀석도 할 수 있다.
별도의 특별한 컴퓨팅 자원 기능은 없고,
오토스케일링 가능한 클러스터를 제공받아 컴퓨팅 자원으로 활용한다.
어찌됐든 ML 특화 서비스인 고로,
Synapse Analytics나 Azure Databricks보다 데이터 변환 성능은 떨어진다.
이상의 기능들을 통한 데이터 수집 솔루션의 정석은 아래와 같다.
① CRMS 또는 IoT등에서 원본 데이터 추출
② Azure Synapse Analytics를 사용하여 데이터를 복사 및 변환
③ 해당 데이터를 Azure Blob에 저장
④ Azure Machine Learning으로 학습 진행
모델 학습 솔루션 설계
<학습 목표> 데이터 수집 솔루션을 설계할 수 있다. 서비스를 선택하여 모델을 학습시킬 수 있다. 모델 배포 옵션을 선택할 수 있다.
앞서 말했듯 모델 학습의 6단계는 다음을 따른다.
문제 정의 - 데이터 가져오기 - 데이터 준비 - 모델 학습 - 모델 통합 - 모델 모니터링
이번엔 이 순서에 따른 흐름을 살펴보자.
1. 문제 정의
문제 정의 단계에서는 세 가지를 정의해야 한다.
모델이 출력할 내용 ML 유형 성능 평가 기준(커트라인)
상식적으로 모델이 출력할 내용이 뭐냐에 따라 ML 유형을 결정하겠지?
그렇게 ML 유형을 나누면 다음의 다섯 가지가 된다.
1. 분류 : 범주값 예측 2. 회귀 : 수치값 예측 3. 시계열 : 미래의 특정 시점 예측 4. 이미지 : 분류, 객체탐지 5. NLP : 텍스트로부터 인사이트 도출
이런 모델 학습에는 알고리즘이 쓰이고, 모델 평가에는 metric이 쓰인다.
요건 에이블에서 많이 했지.
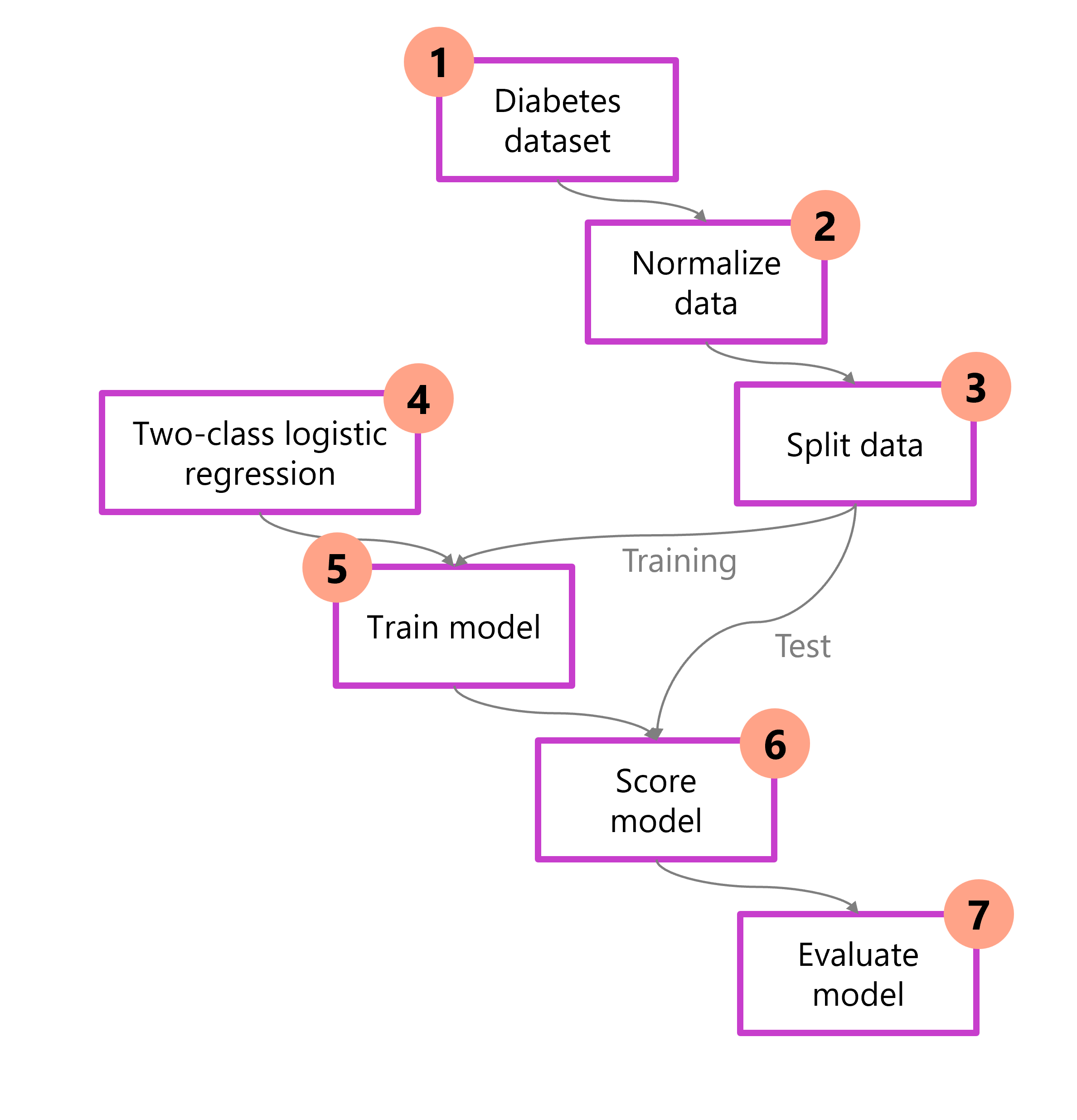
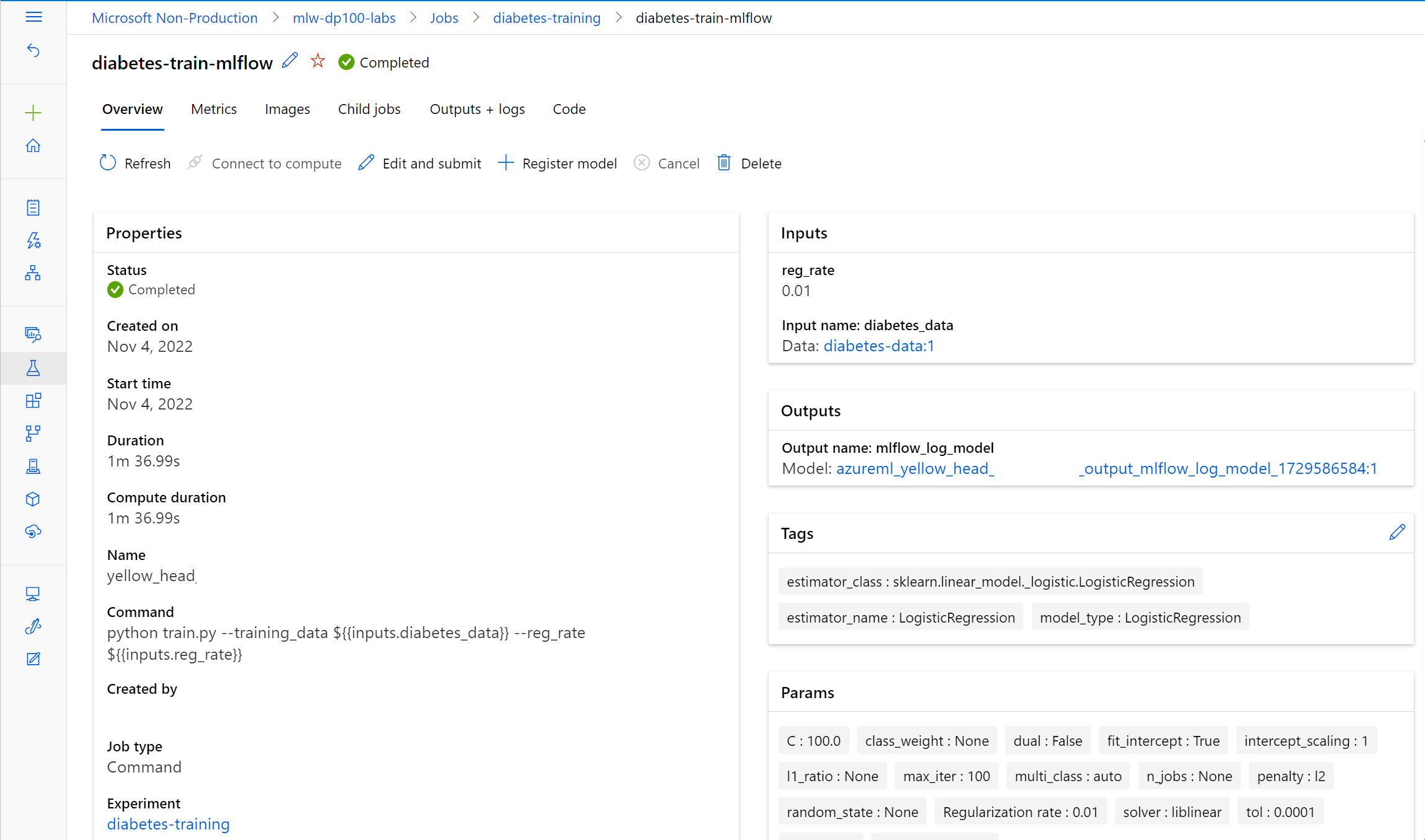
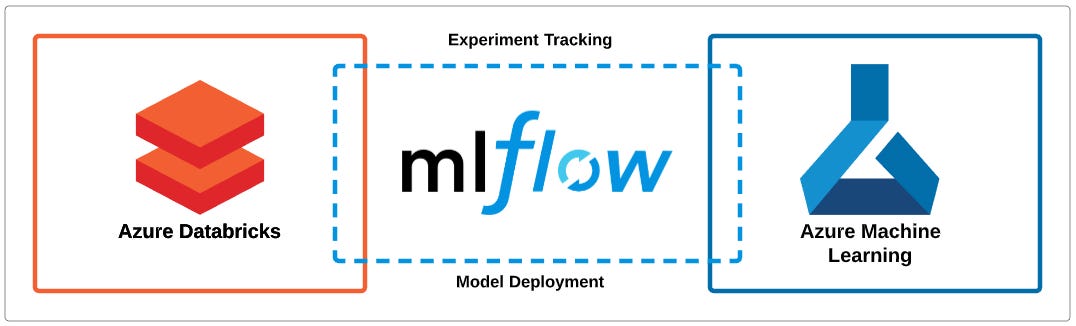
MS Learn에서 제공하는 ML flow.
당뇨병(Diabetes) 데이터를 예시로 쓰고 있다.
target 값이 O/X 이진 분류이다. = 모델이 출력할 내용이 이진 분류이다.
따라서 사용하는 알고리즘은 Logistic Regression을 활용한다.
흐름은 익숙한 방식으로,
데이터셋 -> 정규화 -> 스플릿 -> 모델 학습 -> 성능 평가-> 배포 순서이다..
스플릿된 데이터가 각각 학습과 성능평가에 쓰이는 것 주의.
2. 데이터 가져오기, 데이터 준비
위 과정을 좀 더 익숙한 말로 바꾸면
데이터 수집 - 데이터 로드 - 탐색적 데이터 분석의 3단계로 분류 가능하다.
데이터 수집 솔루션은 앞서 다뤘고, 데이터 로드야 그냥 하면 된다.
탐색적 데이터 분석(EDA)은 엄청 아주 매우 중요하지만,
MS learn에서는 따로 빼 뒀는지 여기서 다루지 않고 넘어간다.
3. 모델 학습
Azure에서 모델 학습에 쓰이는 서비스는 다음과 같다.
일부는 데이터 수집 과정도 기능으로 제공하기 때문에 '데이터 수집 솔루션 설계' 파트에서 봤던 것과 겹친다.
(1). Azure Machine Learning
이름처럼, Azure에서 제공하는 가장 핵심적인 ML 서비스이다. UI 기반의 노코딩 환경과, 파이썬 SDK/CLI 기반의 코딩 환경을 둘 다 지원한다.
(2). Azure Databricks
데이터 분석 플랫폼이다. 따라서 당연히 Spark 기반으로 분산 처리를 수행한다. 데이터를 핸들링 / 처리하는 데 효과적이므로, 학습에 특화된 Azure Machine Learning과 병용하는 경우가 많다.
(3). Microsoft Fabric
데이터 분석가, 데이터 엔지니어, 데이터 과학자 간의 데이터 흐름을 간소화해 주는 플랫폼이다. 데이터 준비 - 모델 학습 - 예측 생성 - 시각화(PowerBI) 과정을 일괄적으로 처리해 준다.
(4). Azure AI Services
미리 build되어 있는 모델들의 모음이다. 다양한 pre-trained 모델을 불러와서 ML 작업에 활용하기 편하다. 모델의 제공 방식이 API이기 때문에 애플리케이션에 통합하기도 용이하다. 자체 학습 데이터에 대한 사용자 설정도 지원한다. 개편해보인다
<컴퓨팅 옵션 설정> 로컬에서는 컴퓨팅 자원의 최적 활용을 위해 자원 활용 상태를 모니터링해야 한다. 하지만 Azure는 당연히 오토스케일링을 지원하므로 다음 옵션 설정만으로 이를 해결할 수 있다.
- CPU / GPU : 말해 뭐하나.
- 범용 / 메모리 최적화 : 범용은 CPU와 메모리가 균형적이다. 메모리 최적화는 메모리가 비중이 높다. -> 소규모 데이터셋에는 범용, 대규모 데이터셋이나 Notebook 환경에서는 메모리 최적화가 좋다.
- Spark : 스파크 클러스터를 통해 분산 컴퓨팅을 시행할 수 있는 옵션이다. 드라이버 노드(메인 노드) / 작업자 노드(분산 노드 추가) 옵션이 있다. 아무래도 분산시킬때는 SQL, RSpark, PySpark처럼 스파크 친화적 언어가 좋다. 파이썬으로 작성한다면 드라이버 노드만 사용할 것
4. 모델 통합(배포)
모델 통합을 위해서는 모델을 엔드포인트에 배포해야 한다.
엔드포인트란 일종의 웹 주소로,
이 주소를 통해 접근한 클라이언트는 자동으로
클라우드나 온프레미스 스토리지에 있는 모델을 로드 및 실행하게 된다.
다시말해 엔드포인트란 저장되어 있던 모델이 클라이언트에게 마중나가는 출구인 셈.
이때 모델 배포자(우리)의 입장에서는 옵션을 하나 줄 수 있는데,
실시간 예측 가져오기(real-time) / 일괄 예측 가져오기(batch) 옵션이다.
이 옵션은 예측을 얼마나 자주 생성하는지,
결과가 매번 하나의 record를 반환활지 아니면 여려 record를 한번에 반환할지,
컴퓨팅 성능은 얼마나 잡아먹는지 등을 고려해 결정한다.
<모델이 요구하는 컴퓨팅 성능과 비용> 실시간 예측 모델은 컴퓨팅의 상시 가동을 전제로 하므로, 컴퓨팅 비용이 지속적으로 빠져나간다.
대신 이때는 한 번에 예측하는 데이터 분량은 적기 때문에 경량 인프라를 제공하는 서비스가 필요하다. 그렇다. 컨테이너 서비스가 필요한 것이다.
Azure에서는 ACI(Azure Container Instance)와 AKS(Azure Kubernetes Service)를 이런 상황에 이용한다.
반면 일괄 예측 모델은 반대로 대규모 데이터 처리를 필요로 한다. 따라서 컴퓨팅 클러스터를 구성해 병렬 처리를 진행하는 게 핵심인데, 이렇게 하면 필요할 때 많은 컴퓨팅 자원을 끌어 쓰고, 불필요할때는 노드를 0개로 줄여 비용을 최소화할 수 있다.
이 기능은 Azure ML을 포함한 다양한 모델 예측 서비스에서 옵션으로 제공한다.
5. 모델 모니터링
모델은 데이터가 변함에 따라 다시금 학습 - 배포 과정을 거친다.
따라서 데이터 과학자는 이 과정들을 파이프라인으로 만들어야 한다.
또한 이 파이프라인에 서비스를 위한 협력자(인프라 팀, 데이터 엔지니어 등등)의 접근을 정의하거나,
협력을 체계화하여 솔루션 확장을 용이하게 해야 한다.
그래야 모델을 서비스에 실제 도입할 수 있다.
이 일련의 과정들을 MLOps(Machine Learning Operations) 아키텍처라고 한다.
DevOps의 머신러닝 버전이라고 생각하면 될 듯.
일반적인 MLOps 아키텍처는 위와 같다.
① 설치 : 솔루션에 쓰이는 각종 Azure 자원을 생성한다.
② 모델 개발(내부 루프) : 데이터 탐색 - 전처리 - 모델 학습 - 평가 과정을 거쳐 모델을 만든다.
③ 연속 통합 : 모델을 패키징하여 저장한다.
④ 모델 배포(외부 루프) : 엔드포인트에 모델을 배포한다.
⑤ 지속적인 배포 : 배포된 모델을 테스트하여 서비스(프로덕션) 환경으로 올린다.
⑥ 모니터링 : 모델과 엔드포인트 성능을 모니터링한다.
위에서 안 다룬건? 모니터링 부분이지.
모델 성능 모니터링의 주요 요소는 다음과 같다.
1. 성능 추적 : Accuracy, F1 Score등으로 모델의 예측 타당성을 평가한다. 2. 데이터 드리프트 탐지 : 데이터가 통계적으로 변하여 분포가 달라질 때, 이로 인해 악화될 모델 성능을 식별한다. 3. 개념 드리프트 식별 : feature와 target의 인과관계가 모종의 이유로 변하면 모델 성능이 변하는데, 그걸 식별한다.
이런 경우에는 모델을 재학습시키는데,
일정에 따라 주기적으로 학습시킬 수도 있지만 특정 성능 metric을 기준으로 재학습 여부를 결정할 수도 있다.
그러니 당연히 재학습 용이하게 파이프라인을 통한 자동화로 코드를 구성해야 하는데,
여기엔 노트북보다 스크립트(.py 확장자) 기반의 개발이 유용하다.
셀을 하나씩 실행시키는 노트북은 그보단 프로토타이핑에 더 적합한 편.
또 이 코드를 관리할 때는 중앙 저장소(Central Repository)를 활용해 주어야 한다.
중앙 저장소는 관계자들이 접근 가능한 공용 공간으로, 협업이 보다 쉽게 이루어지기 때문이다.
Azure에서는 Azure DevOps와 GitHub 이용을 권장하는 편이다.
데이터 과학자 입장에서는 이것들을 Repository로 이용하기에 적합한 도구를 택해 작업하는게 좋은데,
Azure CLI는 Azure ML SDK보다 여기 적합하다.
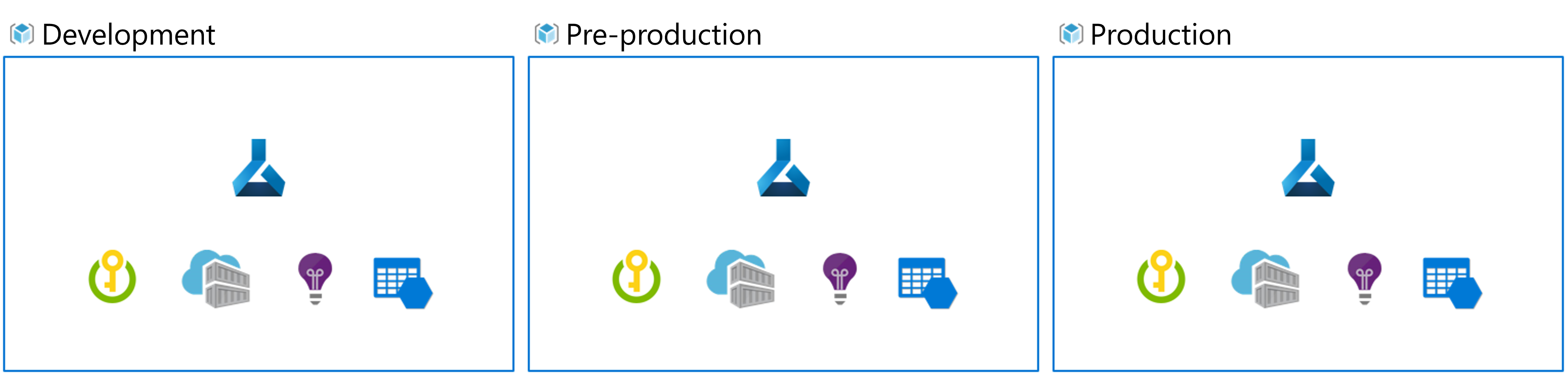
한편 MLOps에서환경이란,리소스 클러스터를 의미한다.
일반적으로 세 가지 이상의 환경을 사용하는데,
그것이개발 환경과사전 프로덕션 환경,프로덕션 환경이다.
보통개발 환경에서모델을 실험하고,
사전 프로덕션 환경에서 모델을배포, 테스트하고,
프로덕션 환경에 릴리즈한다.
이렇게 별개의 환경을 구성하기 때문에,
Azure Machine Learning에서는 각 환경이 별도의 작업 영역에 할당된다.
바로 요렇게.
Azure Machine Learning 활용하기
본격적으로 요녀석을 어떻게 쓰는지 알아보자.
1. 작업 공간 만들기
Azure Portal을 거치거나,
Azure Resource Manager 템플릿을 쓰거나,
Azure CLI를 ML 확장과 함께 쓰거나,
Azure Machine Learning Python SDK를 쓰는 방법을 통해
작업 공간을 만들 수 있다.
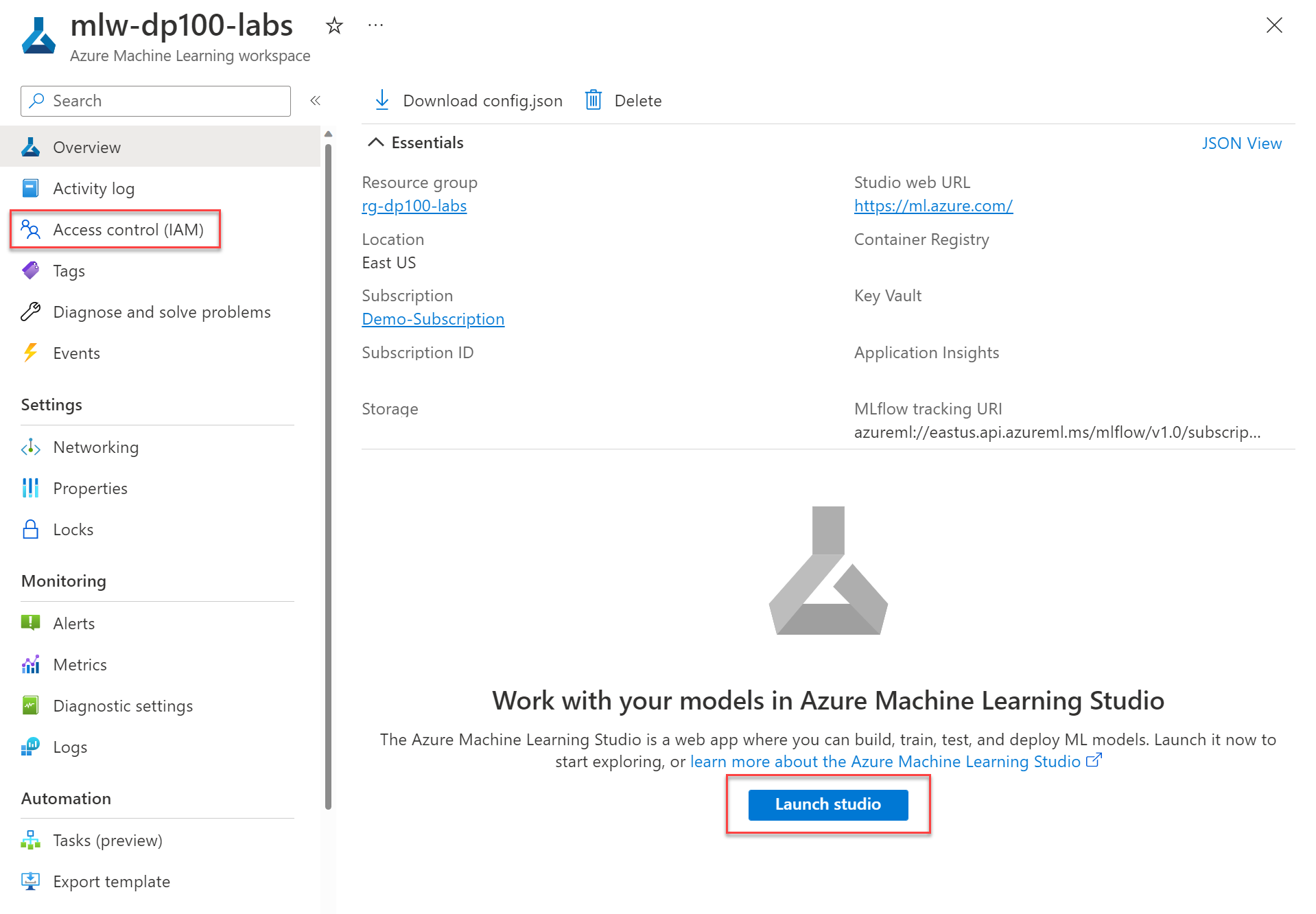
작업 공간은 위와 같이 생겼는데,
각 넘버들은 모두 자동으로 생성되는 Azure 리소스들이다.
정확히는 위에서 3번이 작업 공간인 거지. 2번까지는 인증해서 들어오는 과정이고.
4번은 Azure Machine Learning 인터페이스 자체
5번은 스토리지
6번은 Azure Key Vault(공간에 대한 액세스 제어)
7번은 Application Insights(모델 모니터링 및 관리)
8번은 Azure Container Rehistry(ML 환경의 이미지 저장)
이렇다.
이 작업 공간은 VPC처럼 격리된 환경에서 자원을 할당받아 관리되며,
아래와 같은 인터페이스를 통해 접근 가능하다.
이때 사용자는 다른 사용자 또는 팀에게 액세스 권한을 부여할 수 있으하며,
기본적으로도 아래와 같은 권한이 세팅되어 있다.
소유자: 모든 리소스에 대한 모든 권한 / 다른 리소스에 대한 액세스 권한 부여 가능. 기여자: 모든 리소스에 대한 모든 권한 / 다른 리소스에 대한 액세스 권한 부여 불가능. 읽기 권한자: 리소스 읽기 권한
이외에도 기본으로 제공되는 세부 설정 프리셋이 있는데,
AzureML 데이터 과학자: 컴퓨팅 자원의 생성/삭제와 작업 영역 설정 편집 이외의 모든 작업 권한. AzureML 컴퓨팅 연산자: 컴퓨팅 자원의 생성/삭제 권한
2. 스토리지 관리
작업 공간 자체는 스토리지가 없다.
따라서 모든 데이터는 작업 공간이 참조하는 저장소에 저장되고,
해당 저장소에 대한 접근 권한은 Azure Key Vault에서 관리된다.
이 저장소들은 작업 공간이 만들어질 때 자동으로 생성되며
이때 Azure Storage 계정도 만들어져 ML 작업공간과 저장소들의 연결을 담당한다.
이때 자동으로 생성되는 저장소는 총 4개이다.
1) workspaceartifactstore : azureml 컨테이너. 컴퓨팅과 실험 로그 저장. 2) workspaceworkingdirectory : 작업 공간 섹션 중 Notebook 섹션에서 데이터 로드/세이브할 때 파일이 저장되는 곳 3) workspaceblobstore : Blob Storage. 기본 데이터 저장소. 4) workspacefilestore : Azure Storage 계정 내의 다른 파일 저장.
* 쉬운 설명 - 아티팩트 스토어는 데이터 외의 자원 저장 - 워킹디렉토리는 colab의 contents 처럼 현재 작업중인 파일 공간 - 블롭스토어는 데이터 저장 - 파일스토어는 파일 저장
3. 자산 관리
자산이란 작업 공간 내의모델, 환경, 데이터, 구성 요소 이 네가지를 말한다.
- 모델
사이킷런이든 파이토치든 모델을 만들고 나면
.pkl 확장자의 피클 파일로 저장하거나,
오픈소스 MLflow를 활용하여 MLModel 형식으로 저장 가능하다.
둘 다 모델 + 메타데이터의 형태로 저장되며, 이름과 버전을 지정할 수 있다.
- 환경
사이킷런, 파이토치 이런걸 매 번 깔면 번거롭다.
코드로 존재하는 것 또한 불필요하겠지.
따라서 코드 실행에 필요한 모든 요구사항들은 환경이라는 이름으로 만들어 둘 수 있다.
이 환경은 이미지화하여 Azure Container Rehistry에 저장된다.
- 데이터
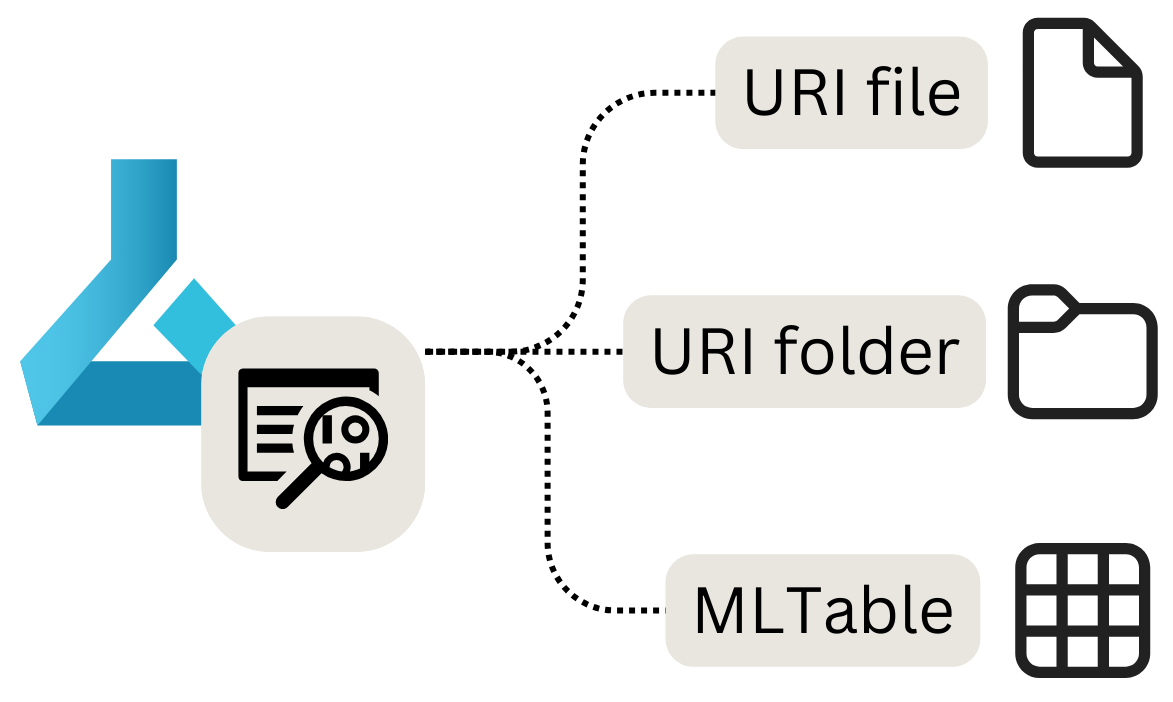
데이터 저장소에 있는거 말고, 데이터 자산을 따로 설정해 놓으면 특정 파일 또는 폴더에 손쉽게 액세스해야 한다.
매번 인증을 거칠 필요가 없다는 뜻.
<데이터 자산의 종류> URI 파일 : 특정 파일에 액세스하는 포인터 URI 폴더 : 특정 폴더에 액세스하는 포인터 MLTable : 테이블을 읽을 스키마와 테이블 자체(파일/폴더)
- 구성 요소
구성 요소란 다른 파이프라인에 써먹을 법한 코드 조각이다.
이걸 구성 요소로 지정해 자산화해 두면 다른 사람이 공유하거나, 이후에 재사용할 수 있다.
4. 모델 학습
모델 학습은
익숙한 방식대로 Notebook에서 하거나,
스크립트(.py)를 실행하거나,
자동화된 ML을 사용할 수 있다.(권장)
자동화된 ML은 위 이미지와 같이 쉬운 UI로 다양한 알고리즘과 하이퍼파라미터를 실험할 수 있다.
보면 분류/회귀/시계열 예측 등 기능을 선택한 후 하위에 있는 세부 옵션을 선택가능하게 되어 있다.
Notebook환경도 제공한다.
위에서 말했듯 이때는 쓰이는 각종 요소(데이터셋 등)이
Azure Storage 계정의 파일 공유에 있는 workingdirectory에 저장된다.
VScode에서 실행하도록 선택하는 옵션도 있다.
스크립트를 쓰는 경우는 이런 인터페이스를 제공받는다.
위에서 말했듯 프로덕션 환경에서는 스크립트 상태로 구성하는 것이 권장된다.
단일 스크립트를 실행하거나('명령')
단일 스크립트 내에서 하이퍼파라미터를 튜닝하거나('스윕')
여러 스크립트로 구성된 파이프라인을 실행할 수 있다.('파이프라인')
5. 작업 수행 툴
작업 공간에서 작업을 수행할 때,
우리는 세 가지 툴 중 하나를 통해 작업 요소들과 상호작용할 수 있다.
- Azure Machin Learning 스튜디오
가장 기본적이고 직관적인 방법.
딸깍딸깍으로 대부분의 작업을 처리한다.
기본적으로 세 개의 기능을 클릭하게 된다.
작성자: 기계 학습 모델을 학습하고 추적할 수 있도록 새 작업을 생성. 자산: 모델을 학습할 때 사용할 자산을 만들고 검토. 관리: 모델을 학습시키는 데 필요한 리소스를 만들고 관리.
다만 작업을 자동화하려면 아래의 다른 도구들로 작업 자체를 코드화해야 한다.
- Python SDK(v2)
파이썬 소프트웨어 디벨롭 키트.
파이썬으로 작업 영역과 상호작용한다. 이게 가장 큰 메리트겠지.
주피터 노트북이든 VScode든 연결해서 사용 가능하다.
!pip install azure-ai-ml
쓰려면 당연히 깔아야 한다.
이후에는 작업 영역과 연결하는데, 세 개의 매개변수를 지정해줘야 한다.
subscription_id: 구독 ID. resource_group: 리소스 그룹의 이름. workspace_name: 작업 영역의 이름.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
이렇게 MLClient 객체를 만들고 나면,
이녀석을 호출함으로써 작업 공간에 접근 가능하다.
일례로 새 작업을 만드는 코드를 써 보자.
from azure.ai.ml import command
# configure job
job = command(
code="./src",
command="python train.py",
environment="AzureML-sklearn-0.24-ubuntu18.04-py37-cpu@latest",
compute="aml-cluster",
experiment_name="train-model"
)
# connect to workspace and submit job
returned_job = ml_client.create_or_update(job)
어휴 매개변수 너무 많다.
이런 나를 위해(...) Python SDK에는 참조 설명서가 있다.
여기에는 Python SDK 내의 모든 클래스, 메서드, 매개 변수가 설명되어 있다.
- Azure CLI
흔히 아는 CLI이다.
근데 사실 데이터 과학자보단 엔지니어나 관리자한테 더 익숙한 사항이지.
그래도 .py 기반이기에 반복, 일관성, DevOps 측면에서 장점이 있다.
작업 공간과 상호 작용시에 상호 작용시에 접두사 az ml이 붙는다.
YAML 파일로 구성을 정의해 두면
비슷한 자산이나 리소스를 반복 생성하기 편하다.
6. 데이터 액세스
데이터에 액세스하기 위해 URI라는 것을 사용한다(URL 아니다)
URI는 액세스할 데이터의 위치를 정의하는 접두사로, 다음의 세 가지가 있다.
http(s) : 퍼블릭 웹이나 Blob abfs(s) : Data Lake azureml : Azure ML 데이터 저장소
따라서 URI를 사용한 코드블럭은 특정 데이터에 반복적으로 접근하기 좋은 키처럼 쓰인다.
위에서 봤듯, 이런걸 데이터 자산이라고 한다.
데이터 자산 생성 예시를 보자.
다음은 데이터 자산 중 URI 파일을 생성하는 코드다.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
my_path = '<supported-path>'
my_data = Data(
path=my_path,
type=AssetTypes.URI_FILE,
description="<description>",
name="<name>",
version="<version>"
)
ml_client.data.create_or_update(my_data)
이렇게 객체화해 둔 데이터 자산은 이제 특정 자산을 순간이동시키는 기제가 되는 셈.
URI 폴더도 비슷하게 만들 수 있지만, MLTable을 생성하려면 스키마도 정의해줘야 한다.
이렇게 해 두면 스키마의 변경이 있을 때도 참조하는 모든 코드를 변경할 필요 없이
자산에 명세된 스키마만 업데이트하면 된다.
python SDK에서는 Data() 클래스를 통해 MLTable 데이터 자산을 만들 수 있다.
Azure Machine Learning으로 데이터 분석하기
이제 진짜 데이터 분석 이야기다.
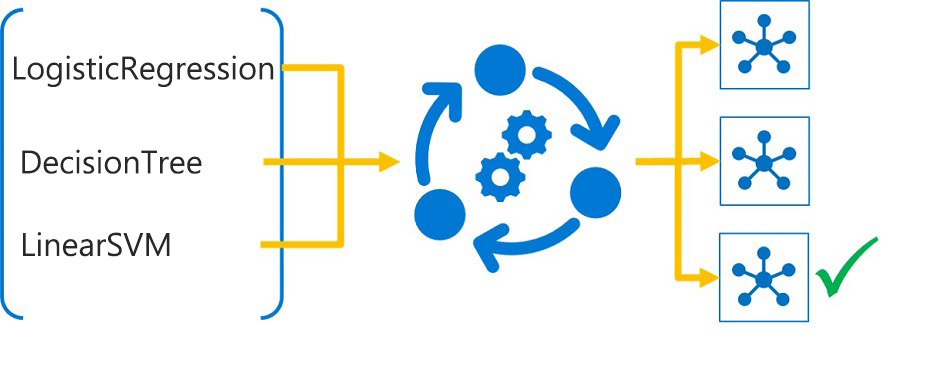
1. 최상의 모델 찾기 기능
위에서 몇 번 언급하긴 했는데, Azure Machine Learning 그 flow가 많이 자동화되어 있다.
따라서 반복 시도가 용이하고, 가장 적합한 모델을 찾는 과정도 자동으로 할 수 있다.
AutoML을 쓰면 데이터로 여러 전처리 + 여러 알고리즘을 자동으로 탐색할 수 있다.
2. 데이터 전처리 구성
일단 이걸 시작하려면, 지금까지 말했던 데이터 수집 - 데이터 자산 구성은 끝난 상태여야 한다.
AutoML은 이렇게 구성된 데이터에 대한 다양한 전처리를 수행하는데,
이는 사용자가 Optional 하게 택할 수 있다.
결측치 제거 가변수화 unique 수가 지나치게 높은 컬럼(식별용 코드라던가) 제거 피처 엔지니어링(연월일 분할 등)
당연히 사용자 커스텀 가능
3. 최적 알고리즘 선택 구성
AutoML은 모델의 목적(분류나 회귀 등)에 맞는 알고리즘 목록을 모두 시험해본다.
사용자가 원하면 몇몇 알고리즘을 제외할 수 있다.
python SDK에서 automl 클래스를 불러와 자동 실험을 돌릴 수 있다.
from azure.ai.ml import automl
# configure the classification job
classification_job = automl.classification(
compute="aml-cluster",
experiment_name="auto-ml-class-dev",
training_data=my_training_data_input,
target_column_name="Diabetic",
primary_metric="accuracy",
n_cross_validations=5,
enable_model_explainability=True
)
이 작업이 완료되고 나면 AutoML 개요 페이지에서 모델들의 summary를 볼 수 있다.
또한 전처리 프로세스의 구체적인 내역도 볼 수 있다.
4. MLflow 활용
아무래도 데이터과학을 공부하는 사람은 보통 Notebook 환경이 편하다.
이때 이 환경에서 ML 실험을 추적 및 로깅해 주는 오픈소스 라이브러리가 있는데,
그게 바로 MLflow다.
# Azure ML 노트북에서
pip show mlflow
pip show azureml-mlflow
# 로컬 노트북에서
pip install mlflow
pip install azureml-mlflow
Azure ML에서는 작업 공간에 이미 컴퓨팅 클러스터가 할당되어 있으므로,
이미 MLflow가 구성되어 있다.
따라서 show로 확인만 해 보면 된다.
azureml-mlflow 라이브러리에는 MLflow와 Azure ML의 통합 코드가 들어 있다.
로컬에서는 인스톨 이후에 Azure ML 작업 영역의 MLflow Tracking URI를 지정해줘야 한다.
MLflow로 AutoML과 같은 실험을 만들 수 있는데,
자동으로 최적 알고리즘을 찾아주는 것은 아니지만
실험에 대한 모든 사항들을 로깅해준다.
import mlflow
mlflow.set_experiment(experiment_name="heart-condition-classifier")
from xgboost import XGBClassifier
with mlflow.start_run(): # 로깅 시작
mlflow.xgboost.autolog() # 자동 로깅
model = XGBClassifier(use_label_encoder=False, eval_metric="logloss")
model.fit(X_train, y_train, eval_set=[(X_test, y_test)], verbose=False)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
mlflow.log_metric("accuracy", accuracy) # 성능 트래킹
코드를 보면 이해가 빠를텐데, 로컬에서 일반적인 알고리즘 성능 테스트를 하는 코드에
MLflow 로깅만 추가하는 식이다.
Azure Machine Learning을 통한 배포
1. Responsible AI(RAI)
Responsible AI(책임 있는 인공지능)는 일종의 규칙이다.
머신 러닝 모델이 공정하고, 투명하며, 신뢰할 수 있도록 개발되고 배포되는 것을 목표로 한다.
이는 머신 러닝이 인간 의사 결정에 활용되기 때문에,
부작용이나 편향을 방지해야만 하기 때문이다.
MS에서는 이에 대해 AI의 다섯 원칙을 제시했다. 1. 공정성과 포용성 2. 안정성과 안전성 3. 개인정보 보호와 보안 4. 투명성 5. 책임
이를 위해 Azure ML은 Responsible AI 대시보드라는 것을 제공한다.
이는 만들어진 모델이 위 원칙을 잘 준수하는지 평가하는 지표로 쓸 수 있다.
여기 쓰이는 도구는 다음과 같다.
Add Explanation to RAI Insights dashboard : 모델 해석에 대한 설명을 생성한다. Add Causal to RAI Insights dashboard : 과거 데이터로부터 어떤 특성이 결과에 미치는 인과관계를 확인한다. Add Counterfactuals to RAI Insights dashboard : 입력값이 변했다고 가정했을 때의 시나리오를 분석한다. Add Error Analysis to RAI Insights dashboard : 데이터 분포를 탐색하여 오류를 일으키는 하위 그룹을 식별한다.
이 RAI tool은 RAI 대시보드를 구성할 때 반드시 하나 이상 포함되어야 한다.
대시보드 구성 시 구성으로는
시작점 : RAI Insights dashboard constructor
종료점 : Gather RAI Insights dashboard
가 있다.
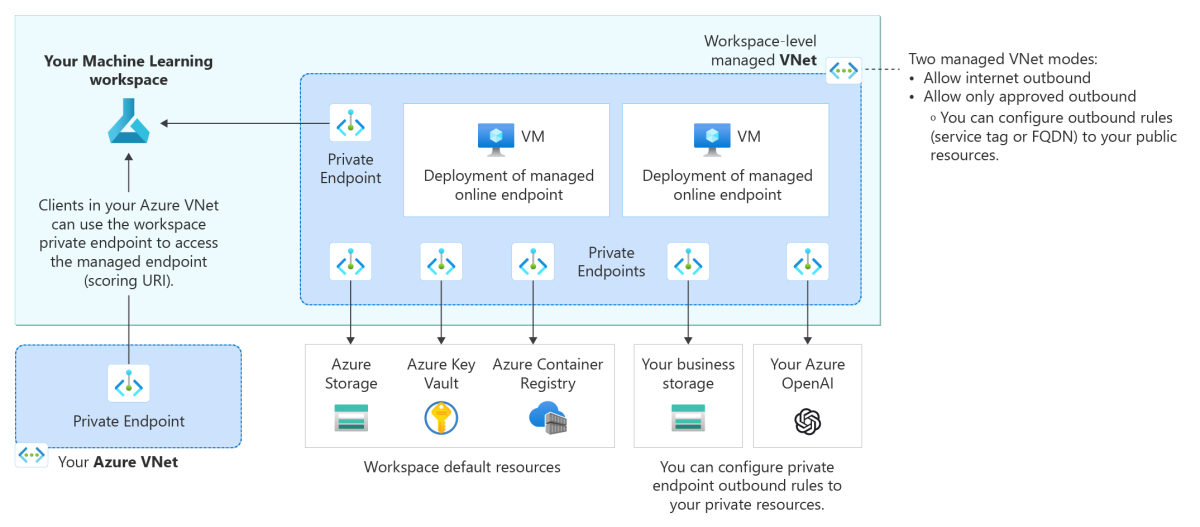
2. 관리형 온라인 엔드포인트에 모델 배포
관리형 온라인 엔드포인트란,
Azure ML에서 사용하는 두 엔드포인트 유형 중 하나다.
위에서 말했듯 엔드포인트는 모델이 나가는 출구인데,
관리형 온라인 엔드포인트와 Kubernetes 온라인 엔드포인트가 있다.
이중 관리형 온라인 엔드포인트는 Azure ML이 모든 인프라와 리소스를 관리하는 엔드포인트이다.
쿠버네티스 온라인 엔드포인트는 다른 팀에서 관리하기 때문에,
데이터과학자 입장에서는 전자만 잘 다루면 된다.
관리형 온라인 엔드포인트를 이용한 VM 격리
관리형 온라인 엔드포인트는 주로 모델 배포를 대비한 테스트에 쓰이며,
배포 시 기본적으로 지정해야 하는 모델 자산, 스코어링 스크립트, 환경을 제외하고
VM 유형과 스케일링 설정만 지정하면 된다는 점에서 매우 편리하다.
이때 MLflow 모델을 배포한다면, 스코어링 스크립트와 환경은 지정할 필요가 없다.
자동으로 로깅되어 있으니까.
<배포의 종류 : Blue / Green>
에이블 시절 잠깐 나왔던 개념이다. 기존에 엔드포인트에 배포된 모델을 Blue라고 하고, 이후에 데이터 변화로 인한 재학습이 일어났을때 이를 같은 엔드포인트에 Green이라는 이름으로 배포한다. 비포/애프터인거지.
Green의 성능이 더 좋다는 보장이 없으니 같은 엔드포인트에서 테스트를 해 보는 것이다. 이러면 서비스 중단을 최소화할 수 있다.