
목차
- 데이터프레임 합치기 : pd.concat(), pd.merge()
- 데이터프레임 세부 조정 : rolling(), shift(), pivot(), melt()
본격적인 가을을 앞두고 마지막 pandas 수업이 끝났다.
코딩마스터스도 40문제 정도 풀었고, 다음주면 드디어 첫 미니프로젝트.
그리고 다음주 토요일은 AICE Associate 시험까지.
바빠서 힘들기도 하고, 신나기도 하는 요즘이다. 집이 점점 개판이 돼 간다
추석동안 못 했던 스터디들이 몰려 좀 많이 늦은 시간이 되었지만, 한번 가 보자.
데이터프레임 합치기
저번 AICE에서 나에게 공포를 선사했던 concat()과 merge() 되시겠다.
아무래도 흔히 보는 xlsx 파일은 시트 하나하나가 데이터프레임이고,
데이터베이스 무결성 측면에서도 데이터테이블은 분산되어 있는 것이 좋겠지.
그에 힘입었는지 최근 관련 시험에서는 데이터 병합 관련된 문제가 많이 나오기도 하는 듯.
어떻게 보면 데이터 전처리에서 가장 전 단계에 수행되는 과정이기도 하다.
- concat()
concat은 'concatenate'에서 따온 말로, 이 단어는 '사슬로 연결시키다'라는 뜻이다.
'catena'가 사슬이니까전에 메이플 할 때 배웠다. 거기서 온 말인가 보다.
여튼, 사슬로 잇듯이, 뒤엉킨다기보단 나란히 붙는다는 이미지로 기억하면 좋다.
섞이듯 들러붙는 건 join에 가까운데, 그건 merge()거니까.
# 모든 열 합치기
pop = pd.concat([pop01, pop02], join ='outer', axis = 1)
# 모든 열 합치기
pop = pd.concat([pop01, pop02], join ='inner', axis = 1)
concat()의 주의점은 세 가지다.
- axis의 방향
- 매개변수의 형태
- join='outer'와 join='inner'의 차이
이 세 가지에 집중해보자.

일단 axis의 방향.
데이터프레임을 다루다 보면 어느 정도 자연스레 'axis 0 = 가로 // axis 1 = 세로'라고 생각하게 된다.
일반적으로 이게 먹힌다만, 본질적으로 axis 0은 행, axis 1은 열이라는 점을 언제나 잊지 말아야 한다.
concat()은 두 데이터테이블을 붙이는 함수이다.
따라서 axis 1로 concat 한다는 것은 열끼리 붙인다는 뜻이 된다.
그러니 표는 자연스레 가로로 길어진다.
axis 0이면 당연히 반대, 행끼리 붙여 세로로 길어진다.
# concat()의 경우
pop = pd.concat([pop01, pop02], join ='inner', axis = 1)
# merge()의 경우
pop = pd.merge(pop01, pop02, how='inner', on='year')
그리고 매개변수의 형태.
아무래도 merge()가 더 많이 쓰이다 보니 기준점이 되는데,
상대적으로 concat()이 소스코드면에서 다른 점들이 있다.
우선 데이터프레임들이 리스트에 담긴다.
강사님 曰, merge()는 두 데이터프레임만 쓰지만 concat()은 수~없이 붙일 수 있어서라고.
그리고 병합계열 함수의 꽃인 병합 방식에서 차이가 난다.
inner, outer의 원리는 같지만, 매개변수명이 다르기 때문이다.
가장 충격적인 건 merge()는 'how='를 쓰는데 concat()이 'join='을 쓴다는 것이다. 조인없는 조인팀
마지막으로 inner와 outer의 차이.
한마디로 정리하자면 inner는 겹치는 행만 붙이고 나머진 제외,
outer는 안 겹치는 행이라도 다같이 불러 오고 다른 데이터프레임 열 값은 NaN으로 처리한다.
흔히 쓰는 비유대로 교집합과 합집합이라 할 수 있겠다.
# inner
pop = pd.concat([pop01, pop02], join ='inner', axis = 1)
k_male k_female f_male f_female
1985 4160 4191 7 6 # pop02에 없는 81~84 자료는 제외.
1986 4899 4888 7 5
1987 5000 4979 6 5
1988 5156 5120 5 5
1989 5305 5261 6 5
1990 5321 5282 5 4
1991 5468 5405 18 14
1992 5500 5435 19 16
1993 5478 5412 19 17
1994 5409 5351 21 19
# outer
pop = pd.concat([pop01, pop02], join ='outer', axis = 1)
k_male k_female f_male f_female
1981 4160 4191 NaN NaN # 81~84 자료를 끌고 왔다.
1982 4160 4191 NaN NaN
1983 4160 4191 NaN NaN
1984 4160 4191 NaN NaN
1985 4160 4191 7.0 6.0
1986 4899 4888 7.0 5.0
1987 5000 4979 6.0 5.0
1988 5156 5120 5.0 5.0
1989 5305 5261 6.0 5.0
1990 5321 5282 5.0 4.
- merge()
merge()는 일반적 SQL문의 JOIN 그 자체다.
두 데이터프레임을 합치되, 기준을 두고 그 쪽 기준의 병합을 시도한다.
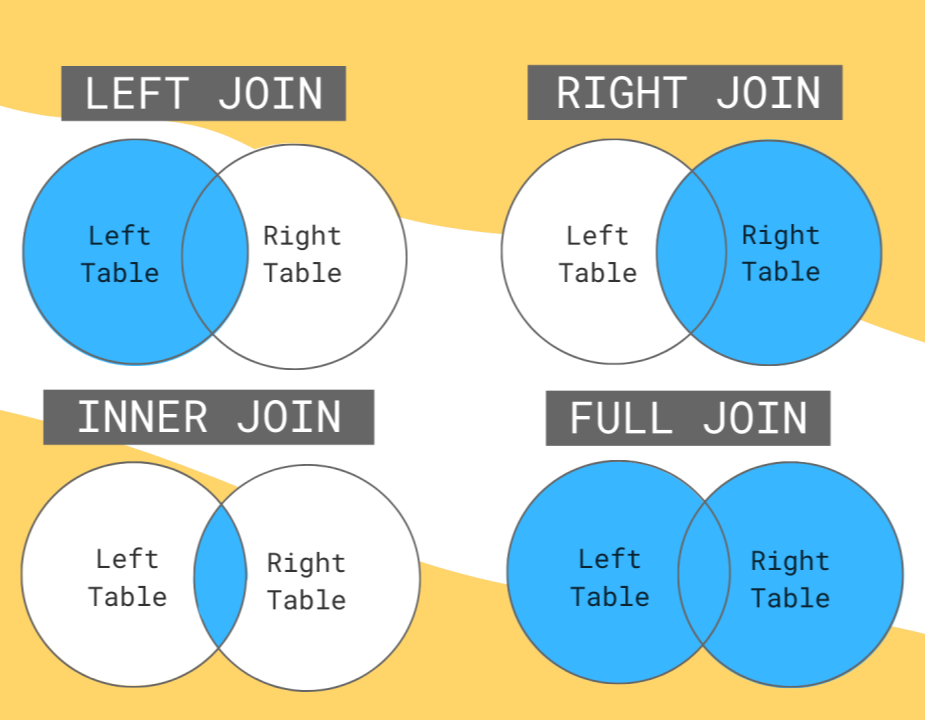
위 그림을 보면, 기본적인 join, 그러니까 merge()의 양상이 보인다. 사실 SQL 자료다 full join = outer join임에 유의.
- inner : 두 테이블의 교집합을 반환한다.
- outer : 두 테이블의 합집합을 반환한다. 어느 한 쪽의 데이터가 없으면 NaN으로 처리한다.
- left : 왼쪽 테이블 기준으로 join한다. 오른쪽에 데이터가 없으면 NaN으로 반환한다.
- right : 오른쪽 테이블 기준으로 반환한다. 왼쪽에 데이터가 없으면 NaN으로 반환한다.
이러다 보니, 두 데이터프레임 간에 크기상 우열이 있으면 inner join이 실제로 left/right join과 같은 경우도 비일비재하다.
다만 저 그림만으로 오해를 하면 안 되는게, merge()의 핵심은 'on=' 매개변수다.
on= 뒤에는 컬럼명이 오고, 이 컬럼이 바로 merge()를 가능케 하는 연결고리(양 쪽에 다 있는 열)인 것이다.
SQL에서 기본키(Primary Key)라고 불리는 그것이다. 맞나?
# pop01과 pop02를 'year' 열 기준으로 inner join하는 것
pop = pd.merge(pop01, pop02, how='inner', on='year')
# pop01, pop02, pop03을 merge()하는 경우
pop = pd.merge(pop01, pop02, how = 'outer', on = 'year')
pop = pd.merge(pop, pop03, how = 'outer', on = 'year')
데이터프레임 세부조정
강사님 피셜 고급 스킬.
확실히 아예 처음 듣는 것도 있고, 깔짝 해보다가 떄려쳤었던 pivot()도 보인다.
다만 이건 참고사항 정도였고, 소스코드도 우리가 직접 쓰는 일은 없었다.
그래서 표로 정리하려다가....
데이터 변경 파트 끝난 김에,
AICE도 준비할 겸 복습도 할 겸 지금까지 배웠던 pandas DataFrame 관련 함수와 메서드를 쭉 나열해 봤다.
분류는 내가 보기 편하게 한 것이다.
col은 열, cols는 열 단독이 들어가도 되고 리스트로 여러 열을 담아도 된다는 뜻이다. row도 마찬가지.
val은 값. 고정값이 들어가기도 하지만 조건식이 들어가기도 한다.
당연히 모든 매개변수가 변수화를 미리 해 두면 편하지만, 특히나 그렇게 주로 쓰는 건 비고에 써 놨다.
| 분류 | 활용처 | 메서드 | 일반적 형태 | 비고 |
| 탐색 | 상위/하위 행 탐색 |
head() tail() |
df.head()/df.tail() | |
| 열 이름 확인 자료형 확인 결측치 확인 |
info() | df.info() | ||
| 기술통계정보 확인 |
describe() | df.describe() df.describe().T |
df.describe().T 가로로 출력 |
|
| 결측치 확인 | isna() | df.isna().sum() | isna() 자체는 bool 반환 | |
| 조회 | 특정 열 조회 조건 조회 |
loc[] | df.loc[row, col] df.loc[:, col] df[col] df[df[col]==값, col] |
df.loc[:, col] = df[col] 조건 조회 시 row 자리에 'df[col]'으로 조건 출력 |
| 집계 | cols A 별 cols B 값 집계 |
groupby() | df.groupby(by=cols A, as_index=False)[[cols B]].집계함수* *집계함수 : mean(), max(), min(), sum(), median(), std(), count() 앞에서부터 평균, 최댓값, 최솟값, 합계, 중간값, 분산, 항목수. agg([])로 여러 집계함수를 묶어 쓸 수 있음 |
|
| 전처리 | 인덱스 리셋 | reset_index() | df.reset_index(drop=True) | inplace=True |
| 인덱스 설정 | set_index() | df.set_index(col) | inplace=True | |
| 열 이름 변경 | rename() | df.rename(columns={col A : col B}) | inplace=True | |
| 열 삭제 | drop() | df.drop(cols, axis=1) | inplace=True | |
| 범주값 변경 | map() replace() |
df[col] = df[col].map({val 1 : val A, val 2 : valB}) 또는 df[col].replace({val 1 : val A, val 2 : valB}) |
map() : 미지정 값 결측화 replace() : 미지정 값 유지 |
|
| 범주화 | pd.cut() pd.qcut() |
df[col] = pd.cut(df[col], bins=bin, labels=label) df[col] = pd.qcut(df[col], int, labels=label) bin = [-np.inf, q1, q2, q3, np,inf] q1 = df[col].describe()['25%'] q2 = df[col].describe()['50%'] q3 = df[col].describe()['75%'] 또는 q1 = df[col].quantile(0.25) q2 = df[col].quantile(0.5) q3 = df[col].quantile(0.75) |
bin = [], label = [] 미리 지정 bin은 주로 4분위값 사용 (q1, q2, q3) qcut은 bin 없이 균등하게 int(n) 등분 |
|
| 결측치 삭제 | dropna() | df.dropna(axis=0) df.dropna(subset=col, axis=0) |
inplace=True | |
| 결측치 대체 | fillna() | df.fillna(value) df[col].fillna(value) |
inplace=True | |
| ffill() bfill() |
df.ffill(value) df[col].ffill(value) df.bfill(value) df[col].bfill(value) |
inplace=True ffill : 앞 row값으로 대체 bfill : 뒤 row값으로 대체 |
||
| interpolate() | df.interpolate(method='linear') | inplace=True | ||
| 원핫 인코딩 | pd.get_dummies() | df = pd.get_dummies(df, columns=cols, drop_first=True, dtype=int) |
cols 미리 지정 | |
| 합치기 | df 연결 | pd.concat() | df = pd.concat([col A, col B, ...], join=str, axis=int) | join : inner/outer axis : 0/1(행병합/열병합) |
| df 조인 | pd.merge() | df = pd.merge(col A, col B, how=str, on=str) | how : inner/outer/left/right on : 연결고리가 되는 열 |
|
| 고급 | 특정기간 열 추가 |
rolling() | df[new col] = round(df[col].rolling(window=int, min_periods=1).집계함수(), 1) |
window : 특정 기간(int) round로 반올림처리 |
| 데이터 끌어오기 |
shift() | df[new col] = df[col].shift(int) | int 만큼 앞에 있는 col의 데이터를 new col에 저장 |
|
| 데이터 돌리기 |
pivot() | df.pivot(index=[cols], columns=col, values=col) | ||
| pivot 취소 |
melt() | df = pd.melt(df, id_vars=[cols], var_name=str, value_name=str) |
id_vars : 유지할 열 시각화를 위해 수행 |
|