지난 포스팅에 이어지는 내용.
[streamlit의 이해, streamlit 메서드]
https://guoyee94.tistory.com/36
이번에는 streamlit으로 차트 그리는 법과 folium map을 알아보자.
streamlit으로 차트 그리기
streamlit은 강력한 차트 기능을 지원한다.
분석가 입장에서는 비분석가에게 정보를 제공하기 위해 사용하게 되는 만큼,
시각화에 힘이 빡 들어간 프레임워크이기 때문이다.
streamlit을 활용해서 차트를 그리는 방법은 세 가지가 있다.
1. Simple Chart
- Streamlit에 내장되어 있음, 따로 import 불필요
- st.line_chart(df) / st.bar_chart(df) / st.area_chart(df)
- 사용법이 간단하다. 별도의 파라미터가 없다.
- 레이블 이름을 지정할 수 없다.
2. Altair Chart
- import altair as alt
- alt.Chart(df).mark_ + 차트종류(line() / bar() / circle())를 통해 차트 객체 생성
- 차트 뒤에 .encode()를 붙여 데이터를 정의해야 한다.
- 차트 객체만 생성하지 말고 st.altair_chart()로 그려 줘야 한다.
3. Plotly Chart
- import plotly.express as px
- px.pie(df), px.bar(df)를 통해 차트 객체 생성
- 차트 객체만 생성하지 말고 st.plotly_chart()로 그려 줘야 한다.
데이터 레이블을 표기할 수 없는 Simple Chart는 일시적인 뷰 생성 외에는 잘 안 쓸 듯하고,
Altair Chart와 Plotly Chart가 주가 되는 것으로 보인다.
두 방법 모두
1. 외부 라이브러리를 import해야 한다는 점
2. <변수 = 별칭.메서드> 이런 식으로 차트 객체를 선언하고, streamlit을 통해 차트를 그린다는 점
을 공통점으로 가지고 있다.
- 데이터 핸들링
본격적인 차트 작성 이전에 데이터프레임을 수정해 주어야 한다.
또 당신입니까 pandas...!
여기엔 이유가 있는데,
streamlit은 matplotlib이나 seaborn과 다르게
Wide format이 아닌 Long format의 데이터를 중심으로 시각화를 지원한다.
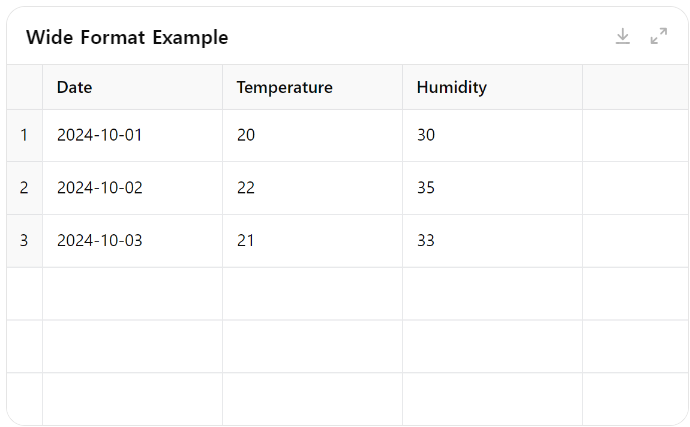
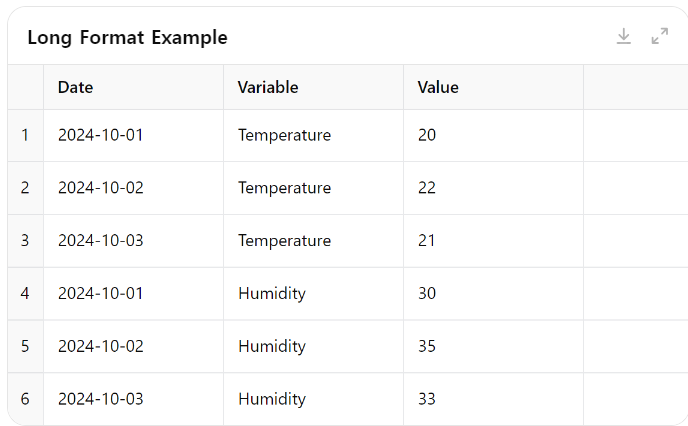
Wide Format : 여러 변수들이 각기 다른 열에 배치된 형식
Long Format : 하나의 열에 여러 변수들이 범주로 나열된 형식
따라서 데이터프레임의 melt를 거쳐야 하는데...
이번주 미프에서 pivot도 나오고 한 기념(?)으로 정리 한 번 하고 가자.
1. pd.pivot
- 기능
Long Format 데이터를 Wide Format으로 변환.
- 필수 파라미터
index:
새롭게 구성될 데이터프레임의 행 인덱스로 사용할 열 이름.
원본 데이터에서 어떤 열을 인덱스로 사용할지 지정한다.
columns:
새로운 열이 될 값(범주).
데이터를 나눌 기준이 되는 열을 지정한다.
values:
열에 배치할 실제 값.
- 자주 사용하는 파라미터
aggfunc: 여러 값이 있을 경우 어떤 집계 함수를 사용할지 정의한다. 기본값은 None.
# 예시
df.pivot(index='Orange', columns='Attribute', values='Values')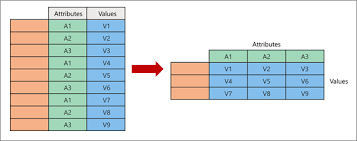
# 여담 : 농구에 '피벗'이라는 게 있다. 한쪽 발을 축으로 삼아 회전하는 기술인데,
그것처럼 한 열의 범주들(세로)을 하나하나 컬럼명(가로)으로 만들어 버리는 개념이다.
2. pd.melt
- 기능
Wide Format 데이터를 Long Format으로 변환.
- 필수 파라미터
id_vars:
식별 변수로 남겨 둘 열 이름.
변형 후에도 그대로 남는 열을 지정한다.
value_vars:
열을 녹일 열 이름들.
변환하려는 열을 지정한다.
지정하지 않으면 나머지 모든 열이 녹는다.
- 자주 사용하는 파라미터
var_name: 녹인 열들의 새로운 이름.
value_name: 값들이 들어갈 열의 새로운 이름을 지정합니다.
# 예시
df.melt(id_vars='Orange', var_name='Attributes', value_name='Values')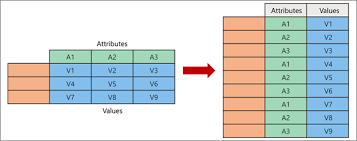
따라서, streamlit에서 시각화를 진행하기 위해서는 대체로
데이터를 melt 해서 사용해야 한다.
# 데이터 불러오기
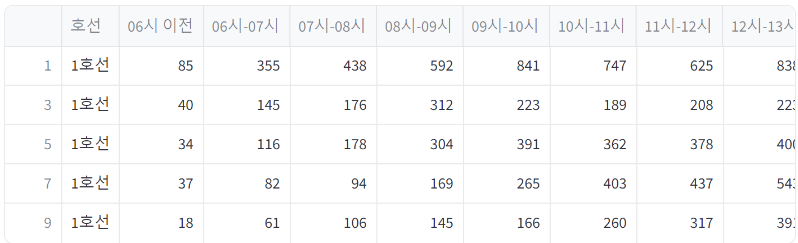
df = pd.read_csv('./data_subway_in_seoul.csv', encoding='cp949')
# 데이터에서 필요한 부분만 선택하여 새로운 데이터프레임으로 저장
df_off = df.loc[df['구분']=='하차', :]
df_line = df_off.drop(['날짜','연번','역번호','역명','구분','합계'], axis=1)
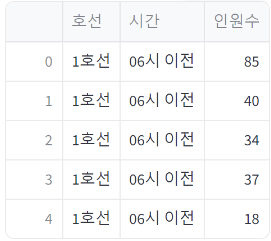
# 데이터프레임 melt
df_line_melted = pd.melt(df_line, id_vars='호선', var_name='시간', value_name='인원수')
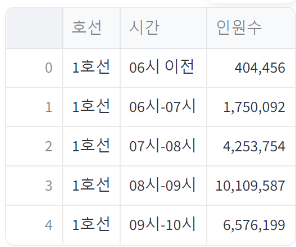
# 필요한 경우 집계까지 수행
df_line_groupby = df_line_melted.groupby(['호선', '시간'], as_index=False)['인원수'].sum()
- Altair Chart
심플 차트는 진짜로 데이터프레임만 집어넣으면 되므로(...) 생략.
Altair Chart의 문법은 제법 복잡하다.
일단 굳이 한 줄로, 그것도 문과식으로 써 보자면...
변수 = alt.Chart(데이터, 제목).mart_차트종류().encode(데이터 정보들).properties(차트 사이즈)
이렇게 차트를 정의하고 어지럽다
st.altair_chart()로 출력하는 방법을 쓴다.
최초에 호출하는 alt.Chart의 대문자 주의.
저 '차트종류' 자리에 보통 line, bar, circle이 들어간다.
circle은 sns의 scatter과 같은 것이다.
'데이터 정보들' 자리에는 차트에 따른 파라미터가 들어가는데,
| 차트 종류 | 파라미터 | 의미 |
| mark_line() | x= | x축 데이터 line 차트이니만큼 보통 시계열 데이터가 들어간다. |
| y= | y축 데이터 | |
| color= | 한 범주를 하나의 line으로 그린다. 여러 범주의 동향을 비교할 때 쓸 수 있다. sns의 hue와 비슷한 파라미터. |
|
| mark_bar() | x= | x축 데이터 |
| y= | y축 데이터. 이번엔 height가 아닌 y임에 유념. |
|
| color= | 입력된 데이터에 따라 색을 구분해 stacked bar로 표현해준다. | |
| mark_circle() |
x=, y= | 역시나 x축, y축 수치-수치를 비교하는 scatterplot이기 때문에 피봇/언피봇이 불필요하다. |
| color= | sns.scatterplot()의 hue와 완전히 똑같은 파라미터 |
정리하고 보니까 .encode()에 x, y, color만 넣어주면 웬만큼 다 된다.
오해해서 미안하다! Altair!
직접 코드를 돌려 보자.
1. 데이터프레임 불러와서 unpivot
import streamlit as st
import altair as alt
import pandas as pd
import plotly.express as px
# melt 함수를 사용하여 데이터프레임 unpivot하기
df = pd.read_csv('https://raw.githubusercontent.com/huhshin/streamlit/master/data_retail.csv')
df_melted = pd.melt(df, id_vars=['date'], var_name='teams', value_name='sales')
# columns 함수를 이용하여 좌-원본 데이터, 우-변환 데이터 출력하기
col1, col2 = st.columns(2)
with col1:
st.text('원본 데이터')
st.write(df)
with col2:
st.text('변경 데이터')
st.write(df_melted)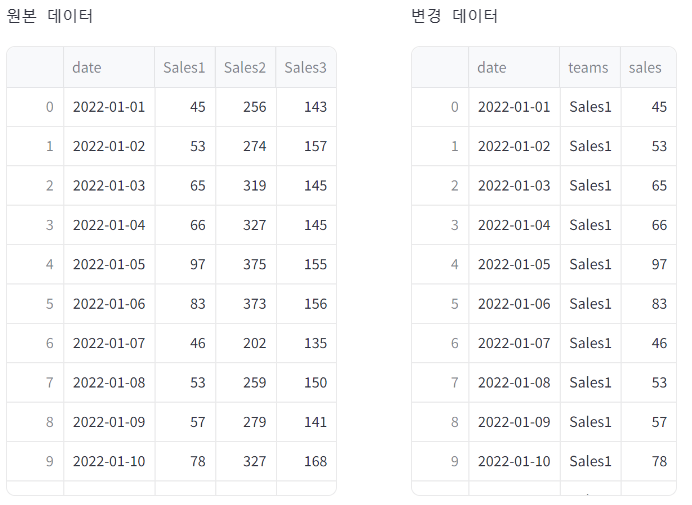
2. line chart
# 차트 선언
chart = alt.Chart(df_melted, title='일별 팀 매출 비교').mark_line().encode(
x='date', y='sales',
color='teams',
strokeDash='teams' ## 점선 스타일
).properties(width=650, height=350) ## 차트 사이즈
# 차트 그리기
st.altair_chart(chart, use_container_width=True) ## 화면에 맞춰 출력하는 옵션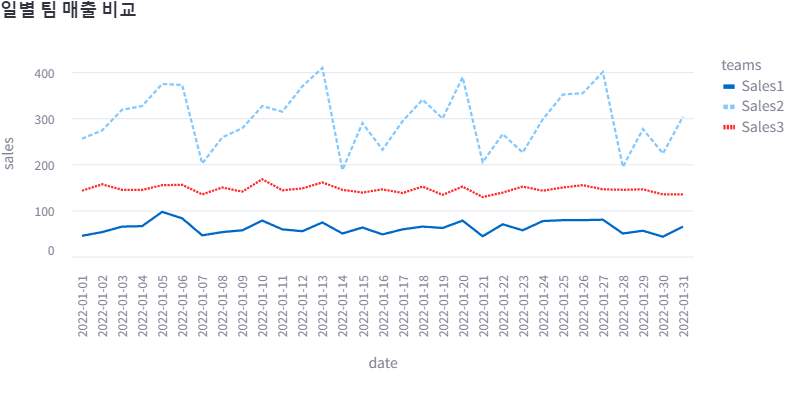
3. bar chart
# 차트 선언
chart = alt.Chart(df_melted, title='일별 매출').mark_bar().encode(
x='date', y='sales', color='teams'
)
# Altair에서 글자 넣기 : 텍스트 구문 따로 정의.
text = alt.Chart(df_melted).mark_text(dx=0, dy=0, color='black').encode(
x='date', y='sales', text=alt.Text('sales:Q')
)
# 차트 그리기
st.altair_chart(chart+text, use_container_width=True)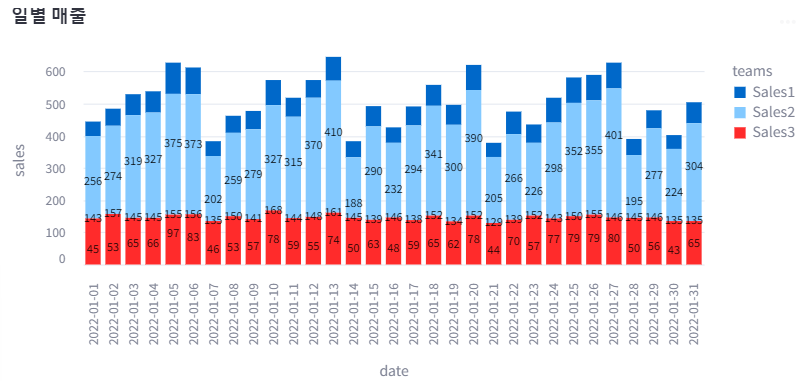
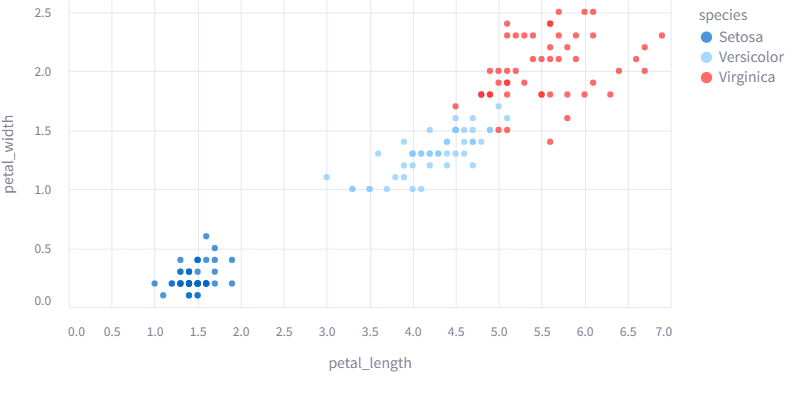
4. circle(scatter) chart
# petal_length, petal_width로 Altair Circle chart 정의
chart = alt.Chart(iris).mark_circle().encode(
x='petal_length', y='petal_width', color='species'
)
# 차트 그리기
st.altair_chart(chart, use_container_width=True)
언피봇이 불필요한 차트이므로, pandas에서 기본제공하는 iris 데이터프레임을 가져다 쓴다.
- Plotly Chart
Ploty Chart는 Simple Chart나 Artair Chart와는 달리
와이드 포맷과 롱 포맷의 데이터를 모두 지원한다.
변수 = px.차트종류(데이터, 데이터 정보들)
이렇게 문법도 단순한데, streamlit 특성상 변수 선언이 필수적이라는 점을 빼면
seaborn과 비슷한 감각으로 사용가능하다.
다만 x, y, color로 다 돌려 쓸 수 있는 Altair와 달리 차트별 파라미터는 신경 써 줘야 한다.
seaborn처럼 첫 매개변수는 데이터프레임 고정이고, 이후로는 조금씩 다르다.
| 차트 종류 | 파라미터 | 의미 |
| px.pie() |
names= | 표의 주인공 컬럼 |
| values= | 'names'의 '무엇'을 집계할 것인지를 지정한다. | |
| title= | 제목 | |
| hole= | 도넛 차트를 만들 때 구멍의 크기 1 이하의 값으로 입력한다.(.3, .1 등) |
|
| px.bar() |
x= | x축, 범주형 컬럼이 온다. |
| y= | y축 단일한 수치형 컬럼이 올 수도 있지만, 리스트에 여러 컬럼을 넣어 stacked bar를 만들 수도 있다. |
|
| text_auto= | 값을 표시할지를 결정한다. bool 형태. |
|
| title= | 제목 | |
| color= | 여기에 컬럼을 줘서 stacked bar를 만드는 것도 가능 |
이렇게 보면 seaborn과 비슷한, 세상 친절한 라이브러리인데
아쉽게도 세상은 그렇지 않다(...)
Plotly Chart의 특징은 label에 대해 다양한 옵션을 제공한다는 것이다.
주로 쓰게 될 것들은 아래와 같다.
- 변수.update_traces(textposition='str', textinfo='str+str...+str')
- 변수.update_layout(font=dict(size=int))
- 변수.update(layout_showlegend=False)
뭐... 읽어만 봐도 하는 역할은 이해가 간다만,
방식이 다소 낯선지라 종종 들어와서 확인하게 될 듯하다.
코드와 실행 결과를 보자.
# select box를 사용하여 탑승지역-Embarked/객실등급-Pclass 선택
tit = st.selectbox('생존자 분석을 위한 항목을 선택하세요.',
['탑승지역분석', '객실등급분석'])
if tit == '탑승지역분석':
sel = 'Embarked'
elif tit == '객실등급분석':
sel = 'Pclass'
else:
write('유효한 항목이 선택되지 않았습니다.')
# columns 함수를 이용하여 좌-pie chart, 우-bar chart 그리기
col1, col2 = st.columns(2)
with col1:
# pie chart 그리기:
fig = px.pie(titanic, names=sel, values='Survived', title=f'{tit} 결과')
fig.update_traces(textposition='inside', textinfo='percent+label+value')
fig.update_layout(height=400, width=400)
fig.update(layout_showlegend=False)
st.plotly_chart(fig)
with col2:
# bar chart 그리기:
fig = px.bar(titanic, x=sel, y='Survived', color='Sex')
fig.update_layout(height=400, width=400)
st.plotly_chart(fig)
이번에는 select box를 이용해 sel 값을 입력받음으로써
사용자가 선택한 데이터의 차트를 출력하는 방식을 사용했다.
데이터는 또 타이타닉 데이터.
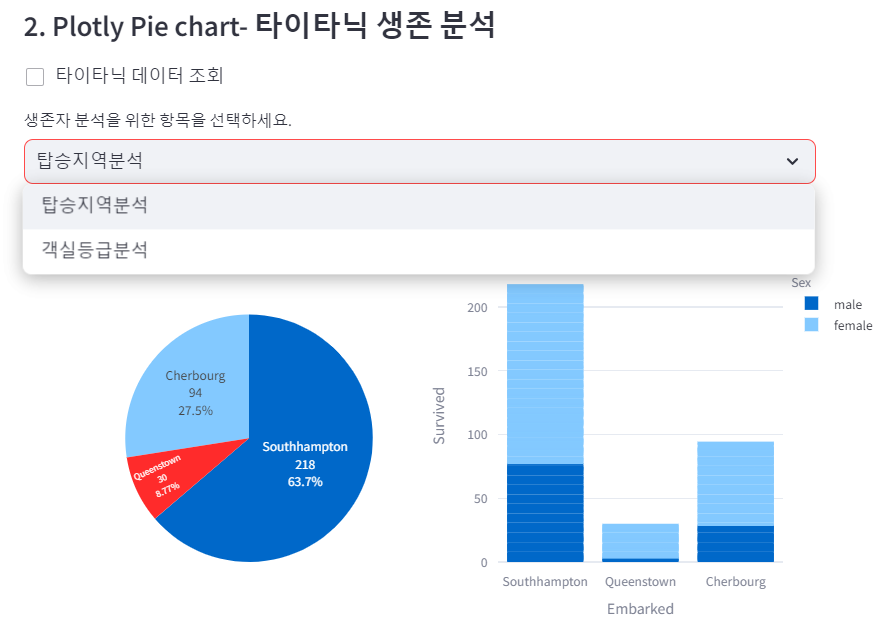
꽤 그럴싸한 결과물이 나온다.
뿌듯.
folium map 사용하기
streamlit에는 st.map()메서드가 있다.
문법도 데이터와 위도(latitude), 경도(longitude)만 입력하면
손쉽게 지도에 scatter를 표시할 수 있게 되어 있다.
사족
지도에 점을 찍는 메서드들은 당연히 위도와 경도 정보가
해당 데이터에 매핑되어 있어야 한다.
다만 심플 차트와 마찬가지로 값을 보여준다거나, 점의 크기를 조절하는 것은 불가능하다.
따라서 이번에는 folium map을 통해 지도에 점들을 찍어 보자.
사용할 데이터 명이 map_data라고 가정했을 때, 기본적인 문법은 아래와 같다.
변수 = folium.Map(
location = [map_data['위도'].mean(), map_data['경도'].mean()],
zoom_start = 2
)
location 파라미터는 지도의 중심을 설정하는 파라미터로,
저렇게 내 데이터의 위도 평균과 경도 평균을 중심으로 설정한다.
zoom_start는 초기 축척이다. 지정하지 않으면 기본값은 10이다.
지도 생성은 이렇게 간단히 가능한데,
마커와 값을 출력하려면 반복문을 써야 한다.
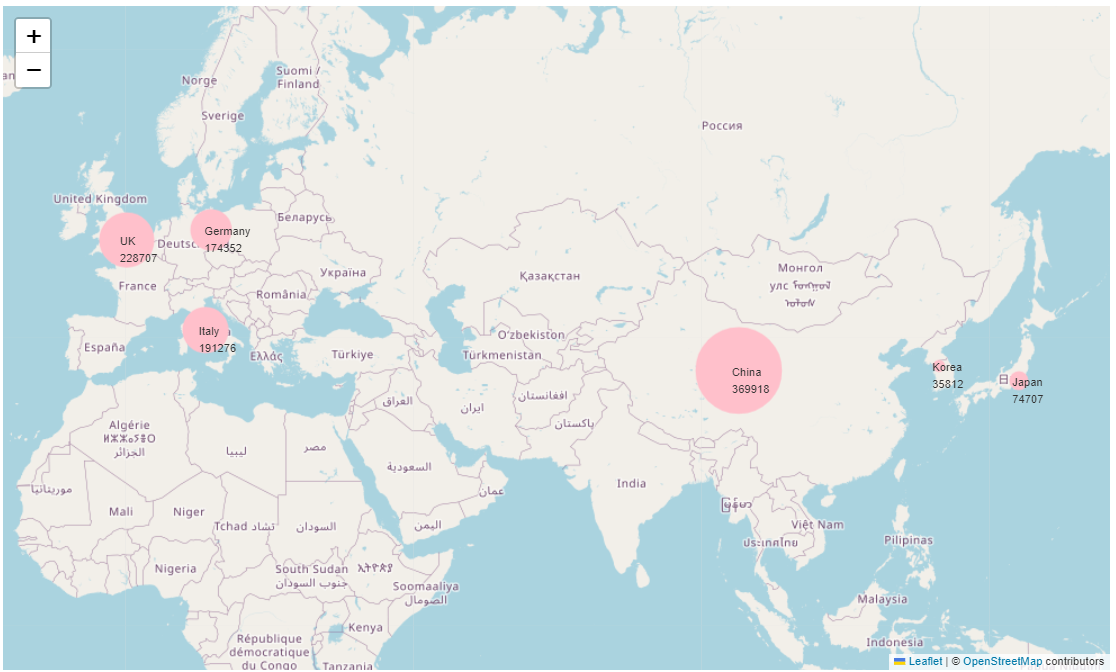
# 지도에 원형 마커와 값 추가
for index, row in map_data.iterrows(): # 데이터프레임 한 행 씩 index, row에 담아서 처리
folium.CircleMarker( # 원 표시 선언
location=[row['lat'], row['lon']], # 원 중심- 위도, 경도
radius=row['value'] / 10000, # 원의 반지름. 적당히 나눠야 크기가 적절하다.
color='pink', # 원의 테두리 색상
fill=True, # 원을 채움
fill_opacity=1.0 # 원의 내부를 채울 때의 투명도
).add_to(my_map) # my_map에 원형 마커 추가
folium.Marker( # 값 표시 선언
location=[row['lat'], row['lon']], # 값 표시 위치- 위도, 경도
icon=folium.DivIcon(html=f"<div>{row['name']} {row['value']}</div>"),
).add_to(my_map) # my_map에 값 추가
# 지도 그리기
# st.components.v1.html : Streamlit 라이브러리의 components 모듈에서 html 함수 사용
# ._repr_html_() : 지도를 HTML 형식으로 표시
st.components.v1.html(my_map._repr_html_(), width=1000, height=800)
다만 저 f-str 부분 이하부터는 수업에서도 전혀 언급이 없었기 때문에 아니면 내가 놓쳤거나
데이터프레임의 각 행을 iterable하게 처리한다는 확인 정도만 하고 넘어간다.