
드디어 머신러닝이다.
아무래도 코딩이 서툰 입장에서는
템플릿 딱딱 정해져 있는 머신러닝이 편하게 느껴지긴 하는듯.
최근 TIL에만 하루에 4시간씩 소비하고 있었는데,
AICE 준비하면서 그나마 미리 알아둔 부분이라 다행이다.
TIL도 중요하지만 이미 넣어버린 ADsP, SQLD 어쩔거야...
잽싸게 복습 끝내고 준비시간을 갖도록 한다.
머신러닝이란
넓은 의미는 뭐... 넣어 두고,
좁은 의미로 머신러닝이란
컴퓨터에게 데이터를 x(feature), y(target) 형태로 줌으로써
x와 y가 어떤 관계를 가지고 있는지 학습시키는 것이다.
우리가 학습을 시키는 대상, 또는 학습을 완료한 주체를 '모델'이라고 부르며,
이 모델에게 실제 데이터(x)를 줘서 우리는 알아내지 못하는 y를 예측시키는 것이 궁극적 목적이다.
유명한 비유를 인용하자면, x는 시험지고 y는 답이랄까...
시험지와 답으로 많이 공부를 해 두면,
실제 x같은 문제를 접하면 밝혀지지 않은 y를 예측할 수 있을 것이다
머신러닝의 과정
개인적으로 머신러닝은 이론에 대한 이해가 중요하다고 생각한다.
하지만 그 과정을 구체적으로 모르면 이론 자체가 머리에 안들어오더라.
따라서 머신러닝이 어떤 과정을 거쳐 이루어지는지부터 살펴보자.
머신러닝의 기본적인 과정은 다음과 같다.
1. 데이터 전처리
2. 머신러닝 모델 호출
3. 모델 선언
4. 모델 학습
5. 모델 테스트
5-1. 예측값 생성
5-2. 예측값과 실젯값 비교
만약 5의 과정이 나쁘다면, 다시 앞의 어느 단계로 넘어가야겠지.
각 과정에 대해서 코드 없이, 개념적으로 한 번 알아보자.
1. 데이터 전처리
데이터를 머신에 넣기 좋은 상태로 만드는 것.
전처리된 데이터는 여러 조건을 만족해야 한다.
자세한건 나중에 종합 정리에서 다루고, 오늘 배운 것만 다루자면
- 결측치가 없고
- 범주형 변수가 없으며
- train 데이터셋과 test 데이터셋이 나누어져 있어야 한다.
이를 위해 결측치 처리 / 가변수화 / train_test_split을 통해 데이터를 다듬어 준다.
2. 머신러닝 모델 호출
sklearn으로부터 적절한 모델을 import한다.
target이 이진 범주인지, 다중 범주인지, 수치인지에 따라 호출하는 모델이 다르다.
3. 모델 선언
변수(객체) 'model'에 호출한 모델을 함수 형태로( = ()를 넣어서) 선언한다.
이후의 과정은 대체로 해당 모델이 가진 메서드(fit, predict)를 활용하여 진행된다
4. 모델 학습
model이 가진 fit() 메서드로 학습을 진행한다.
이때 train 데이터셋을 매개변수로 넣어 주면 된다.(x_train, y_train)
5. 모델 테스트
학습이 완료된 모델이 train 이외의 데이터도 잘 예측하는지 검증한다.
미리 분리해 둔 x_test를 기반으로 predict 메서드를 사용하여
모델이 예측한 y값(y_pred)를 도출하고, 이를 x_test에 대응되는 실제값 y_test와 비교하는 원리다.
필요에 따라 두 결과를 시각화하여 비교하기도 한다.
머신러닝 문제의 유형
아까 말했듯 머신러닝을 결국 y(target)를 예측하도록 만드는 것이 목적이다.
따라서 y가 어떤 자료냐에 따라 모델이나 metric이 달라지는데,
크게 나누면 2가지, 작게 나누면 3가지 유형으로 볼 수 있다.
오늘은 지도학습만을 공부하기 때문에, 2가지 유형(회귀/분류) 나누어 살펴보겠다.
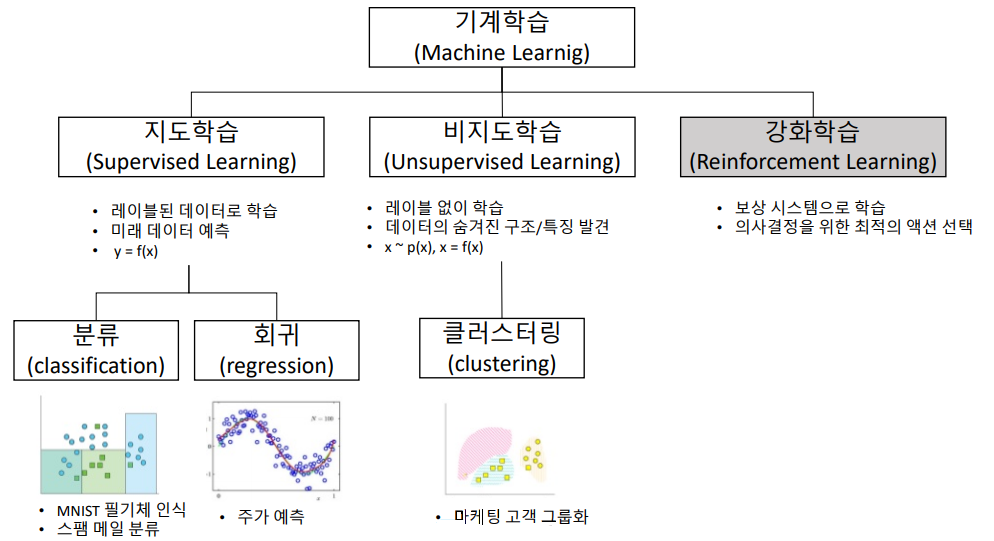
- 분류 문제
타겟이 범주형인 경우, 분류 문제라고 할 수 있다.
여기서도 이진 범주냐, 다중 범주냐에 따라 모델의 차이가 있지만...
일단 지금은 '범주형 = 분류 문제' 까지만 잡고 가자.
분류 문제에서 훌륭한 모델이란 뭘까?
범주형 데이터에 대한 예측을 잘 했다는 것이 무슨 뜻일까?
모델이 범주형 데이터를 예측했다면, 결과는 '맞췄다/틀렸다'뿐이다.
'답에서 얼마만큼 멀다'라는 말은 못한다는 소리.
따라서 분류 문제의 모델은 몇 개를 맞췄느냐를 중점으로 판단하게 된다.
<분류 문제에 쓰이는 모델 검증 지표>
- accuracy_score(정확도)
전체 예측 중 맞춘 비율. 다만 자료가 불균형하면 높은 정확도가 의미가 없을 수 있다.
무슨 말이냐면....
어떤 데이터가 a 90개, b 10개로 구성되어 있다고 하자.
그럼 냅다 a로 밀면 90%는 맞는다.
암만 봐도 이게 좋은 모델은 아니겠지??
- recall_score(재현율)
실제로 A인 데이터를 모델이 A라고 판단한 비율.
엄한 걸 A라고 할지언정 놓치는 A가 있어서는 안될 때 중요한 지표가 된다.
- precision_score(정밀도)
모델이 A라고 판단한 것 중에서 실제 A였던 것의 비율
A를 좀 놓칠지언정 엄한 걸 A라고 하면 안될 때 중요한 지표가 된다.
- classficaion_report
상기한 정보들을 리포트처럼 상세히 보여준다.
- confusion_matrix
- TP (True Positive): 실제로 A인 샘플을 A로 예측한 경우.
- TN (True Negative): 실제로 ~A인 샘플을 ~A으로 예측한 경우.
- FP (False Positive): 실제로 ~A인 샘플을 양성으로 A로 잘못 예측한 경우.
이 4가지 요소를 바탕으로 표를 만들어 준다.
- FN (False Negative): 실제로 A인 샘플을 -A로 잘못 예측한 경우.
- 회귀 문제
타겟이 수치형일 때 회귀 문제가 된다.
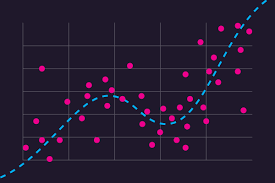
회귀 문제의 모델 평가는 추세선(모델의 예측치)가 실제 값에서 얼마나 떨어져있느냐를 근거로 한다.
저 '얼마나 떨어져 있느냐'를 오차(error)라고 하며, 모든 평가지표의 기준이 된다.
분류 모델에서는 '얼마나 많이 맞췄나'가 기준이니까 높을수록 고성능이었지만,
회귀 모델은 오차가 지표이다 보니 낮아야 좋은 모델이다.
<회귀 문제에 쓰이는 모델 검증 지표>
- MAE(mean_absolute_error)
오차 절댓값들의 평균.
당연히 오차의 절댓값들을 다 합친 후 자료 수만큼 나누어 구한다.
직관적이면서도 이상치에 민감하지 않다는 특징이 있다.
- MSE(mean_squared_error)
오차 제곱 합의 평균.
제곱을 취했기 때문에 실제 값 변동에 민감하다.
이상치라도 있었다간 휙휙 증가하는 것을 볼 수 있다.
다시 말해 다른 지표보다 오차에 대한 패널티가 크다.
그래서 큰 오차가 나면 안되는 모델에서 주로 쓴다.
한가지 더, 제곱값이기 때문에 미분 가능한 지표라는 장점이 있다.
추후 딥러닝에서 배울 손실 함수 부분에서 MSE가 기본값인 것도 그런 이유.
- RMSE(root_mean_squared_error)
MSE에 루트를 씌운 것.
루트로 오차 크기를 줄였기 때문에 MAE처럼 직관적이고,
제곱 계산 이후에 루트가 들어가므로 MSE처럼 오차에 대한 패널티가 크다.
장점을 합쳤다....기 보다는, 둘 사이의 절충적인 지표라고 이해할 수 있다.
- MAPE(mean_absolute_percentage_error)
MAE를 퍼센트로 나타낸 것.
상대적 비교가 용이하지만, 강사님 말씀에 의하면 잘 안 쓴다고.
- R-squared (R² / 결정 계수)
MSE가 직관성이 낮아서, 이를 표준화한 지표.
전체 오차 중, 우리가 극복한 오차의 비율을 나타낸다. 따라서 높을수록 좋다.
SSR / SST : 평균-실제값 오차 중에서, 평균-모델 오차의 비중. 이게 크단건 평균보다 크게 낫다는 뜻.
머신러닝 과정 코드
흔히들 "머신러닝은 4줄로 끝난다."라고 한다.
문제유형에 따라 모델이 다르지만, 방법의 측면에서만 보자면 맞는 말이다.
하지만 본 강의에서 train_test split도 다루었기에, 그것까지 더하면 좀 늘어난다.
# target 확인
target = '대상 열'
# 데이터 분리
x = data.drop(target, axis=1)
y = data[target]
# 모듈 불러오기
from sklearn.model_selection import train_test_split
# 7:3으로 분리
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1, test_size=0.3)
# 1단계: 불러오기
from sklearn.모델 클래스 import 모델명
from sklearn.metrics import 평가지표
# 2단계: 선언하기
model = 모델명()
# 3단계: 학습하기
model.fit(x_train, y_train)
# 4단계: 예측하기
y_pred = model.predict(x_test)
# 5단계 평가하기
평가지표(y_test, y_pred)
뭐 그래도.... 한글로 써 놓은 부분 제외하면 다 고정이긴 하다.
템플릿이 나오기 때문에 코드 자체가 어렵지 않은 것도 사실이다.
다만, 분류 문제에서는 train_test_split()에 stratify=y 파라미터를 넣어줄 것.