
특히 뒤풀이가 폭풍같이 지나가버린 2차 미니프로젝트.
지금 안건데 지난주 후기를 안썼더라.
숙제가 늘어나는 기분.
어쨌든 미니프로젝트 후기는 이번 주말에 쓰기로 하고,
이번주 목-금은 '허신' 강사님께 '데이터 분석 표현'이란 걸 배운다.
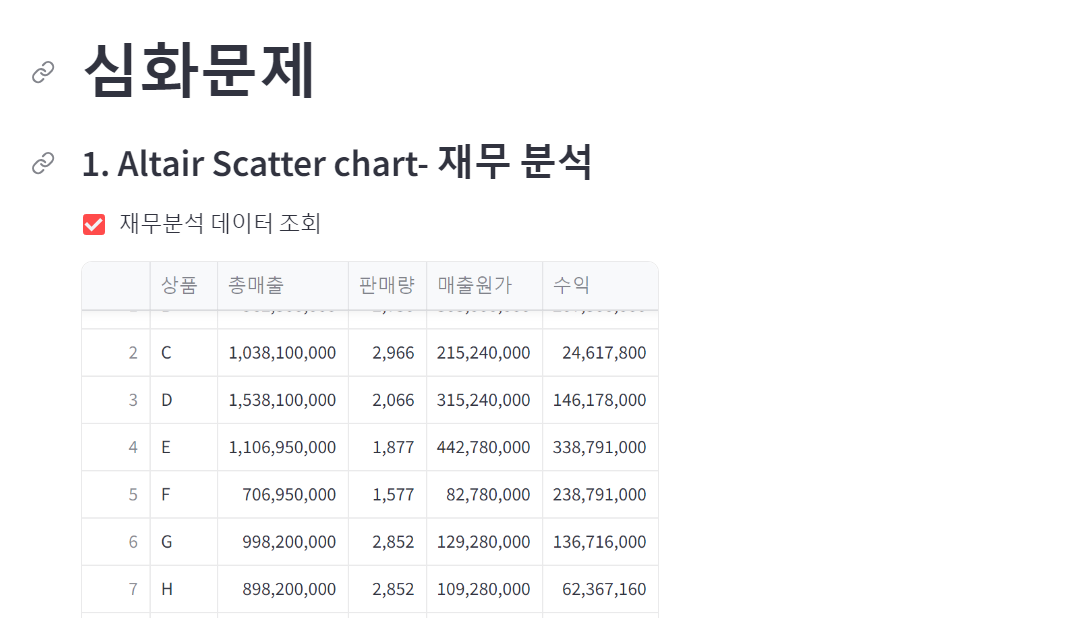
| 월 | 화 | 수 | 목 | 금 |
| 2차 미니프로젝트 | 한글날 | 데이터 분석 표현 | ||
Jupyter Notebook 환경을 벗어나,
실무에선 시각화 및 인터페이스 재현을 이렇게 진행하는건가...? 를 맛볼 수 있는 시간이었던 것 같다.
Streamlit의 이해
Streamlit은 파이썬으로 쉽게 데이터 애플리케이션을 만들 수 있게 해주는 오픈소스 프레임워크이다. 복잡한 웹 개발 지식 없이도 간단한 코드로 대화형 웹 애플리케이션을 개발할 수 있으며, 특히 데이터 분석, 머신러닝 모델 시각화 및 대시보드 구축에 유용하다. Streamlit을 사용하면 데이터 과학자가 익숙한 파이썬 환경에서 바로 웹 애플리케이션을 작성할 수 있어, 실시간으로 분석 결과를 시각적으로 표현하고 공유하는 데 적합하다.
설명을 봤을 때는 거의 빛과 소금이다.
한방에 폼나는 정보 공유를 가능케 한달까.
데이터 분석 후에 일일이 노트북 파일 띄워 가며,
또는 협업 툴에 매번 따로 업로드 해 가며 브리핑할 필요가 없게 해 주길 기대해 본다.
물론 페이지를 빠르게 구축할 수 있다면 말이지.
streamlit의 공식 웹페이지. 각종 기능과 레퍼런스가 준비되어 있다.
아마도 자주 가게 될 것 같으니 북마크.
그래서 오늘의 강의는 'streamlit에는 이런 기능이 있다!'에 주안점이 있었다.
기본적인 기능에 들어가기 전에, 얘가 어떤 원리로 동작하는지를 가볍게 살펴보자.
우선, streamlit(별칭은 st)은 지금까지 써 온 노트북 파일(.ipynb 확장자)이 아니라
파이썬 파일(.py 확장자)에서 작성한다.
※ .ipynb 파일과 .py 파일의 차이
.ipynb 파일
대화형 문서 형식으로, 코드와 텍스트, 그래프 등을 함께 포함할 수 있어 데이터 분석이나 교육 자료에 적합하다.
셀 단위로 코드가 실행된다.
.py 파일
순수한 파이썬 코드 파일로, 애플리케이션 개발이나 자동화 스크립트 작성에 주로 사용된다.
전체 스크립트가 한번에 실행된다.
왜인고 하니, st는 상술했듯 웹 기반 애플리케이션을 결과물로 뱉기 때문에,
노트북 환경에서는 실행 결과를 확인할 수 없다.
따라서 터미널에서 해당 .py 파일의 디렉토리로 옮긴 뒤,(cd 폴더명)
streamlit run 파일명 명령어로 웹페이지를 띄워야 한다.

이 페이지 우측 상단의 'rerun'(또는 단축키 r)을 누르면
해당 웹페이지를 작성한 .py 파일의 변경사항이 적용된다.
또는 에러가 뜬다.
.py 파일에 수정된 사항을 저장해야만 rerun 버튼이 나타나니 참고.
따라서 아직 streamlit 작성이 낯선 주인장으로서는
[코드작성 - 저장 - Alt + Tab - rerun - 절망(...)]
이를 반복해 가며 페이지를 완성해 나가게 된다.
지금부터 나름대로 중요하다고 생각되는 컬럼들을 짚어 보자.
일단 기본 기능 한눈에 보기
import streamlit as st
import pandas as pd| 분류 | 명칭 | 기능 | 매개변수 |
| Text elements | st.write() | 출력. 받은 자료형을 알아서 판단한다. 아마도 가장 자주 쓰게 될 기능 |
문자열, 데이터프레임, 그래프, 차트, 수식 등 다양함 |
| st.title() st.header() st.subheader() st.text() |
문자의 두께, 크기 등이 다른 글들을 출력 | 문자열 | |
| st.markdown() | 마크다운 문법에 따르는 출력 | 문자열, 마크다운 문법이 적용 | |
| st.code() | 코드블럭 안에 출력, clipboard copy도 지원된다. |
문자열 | |
| st.latex() | 문자열을 수식으로 바꾸어 출력 ex) ^ : 지수, \sum : 시그마 |
문자열 형태의 수식 1. 수식은 보통 길기 때문에 라인 컨티뉴에이션(''' ''')을 사용함 2. \n의 줄바꿈을 무시하기 위해 r 포맷을 사용함 |
|
| st.divider() | 구분선을 넣는다. | ||
| st.caption() | 각주처럼 작고 희미한 문자열 출력 | 문자열 | |
| Media elements | st.image() | 이미지 삽입 | 이미지 파일 경로 |
| st.audio() | 오디오 삽입, 볼륨 조절도 된다. | 오디오 파일 경로 | |
| st.video() | 비디오 삽입 | 비디오 파일 경로 | |
| Data display | st.metric() | 측정값. 변동치도 따로 명시할 수 있다. |
label='제목' value='값' delta='변동량' |
| st.dataframe() | 데이터프레임을 출력 그냥 write()로도 가능한 게 함정 |
데이터프레임 | |
| st.table() | 고정식 표 출력 | 데이터프레임 | |
| st.data_editor() | 데이터프레임을 웹에서 수정할 수 있다. | 데이터프레임 | |
| Input Widgets | st.link_bitton() | 말 그대로 링크 버튼 | 문자열 : 위젯 이름, 링크 경로 |
| st.radio_button() | 라디오처럼 여러 버튼 중에 하나를 선택하면 나머지는 취소되는 방식 |
문자열 : 안내문, 리스트 : 버튼명 |
|
| st.button() | 누르면 불 들어오는 버튼 한번 누르고 나면 취소는 안 됨 |
문자열 : 안내문 if문으로 누르기 전/후 구분 |
|
| st.checkbox() | '로봇이 아닙니다' 같은 거 | 문자열 : 체크박스 명 if문으로 체크/비체크 구분 |
|
| st.toggle() | on/off식 토글 버튼 | 문자열 : 버튼명 | |
| st.selectbox() | 드롭다운 박스 생성 | 문자열 : 안내문 리스트 : 드롭다운 항목명 |
|
| st.multiselect() | 쇼핑몰 태그검색처럼 여러 요소를 선택 | 문자열 : 안내문 리스트1 : 선택가능한 항목 리스트2 : 기본 항목 |
|
| st.text_input() st.number_input() st.date_input() st.chat_input() |
특정 자료형을 input 받는다. 파라미터가 다양하지만 생략. |
||
| st.slider() | 드래그로 끌어서 수치를 조절할 수 있는 위젯 날짜 바탕의 데이터프레임을 읽어들일 수 있음 |
문자열 : 안내문 int1, int2 : 허용 구간 int3 : 최초 세팅 값 [int3, int4] : 최초 세팅 구간 int 대신 float/datetime 가능 |
|
| Layouts | st.sidebar() | 사이드바를 정의함 | with 구문으로 블록화하여 사용 |
| st.columns() | 여러 요소를 한번에 표시 1. 개인적으로 plt.subplot() 같은 기능이라고 생각 |
int. int값만큼 변수를 선언해야 함. ex) col1, col2 = st.columns(2) |
|
| st.tab() | 여러 요소를 한번에 표시 2. 브라우저의 탭 같은 방식의 영역 정의 |
list. 길이만큼 변수를 선언해야 함. ex) tab1, tab2 = st.tab([v1,v2]) |
만들다가 깨달은 점.
streamlit을 공부하며 묘하게 낯선 느낌을 떨칠 수가 없었는데,
그 이유를 알 것 같다.
st. 메서드들은 대체로 '변수에 집어넣는 것만으로도 출력이 발생다.'
한 번 예를 들어 보자. pandas의 경우,
test = df.head()
이 코드는 아무런 출력을 뱉지 않는다.
test에 df의 상위 행들이 저장되었지만, 사용자 입장에서 보이는 것은 없다.
하지만 streamlit은 모든 동작이 웹 어플리케이션을 생성하기 위한 것이다.
그러니 사용자에게 보이는 뭔가를 띄워 주는 것 자체가 메서드의 목적인 것이다.
때문에
test = st.slider('아무말', 0, 100)
이렇게 변수에 집어넣기만 해도 웹에는 위젯이 생성된다.
위 기능들 중 나름대로 중요하다고 생각하는 녀석들을 뽑아 보자.
- st.write() : 워낙에 자주 쓸 녀석. 공부할만한 요소가 크게 있지는 않지만 친해져 두어야 한다.
- st.radio_button(), st.checkbox(), st.selectbox() : input 3형제, 데이터분석 특성상 자주 쓸 듯하다.
- st.slider() : 사용자 입장 직관성 GOAT. streamlit은 결국 비분석가를 위한 것이므로... 중요하겠지?
- st.columns(), st.tab() : 레이아웃은 당연히 깔끔해야 한다.
이 녀석들 중에서도 input 3형제와 슬라이더에 대해 한 번 더 복습해 보고 넘어가자.
- 라디오버튼, 체크박스, 셀렉트박스
# RadioButton
st.header('Radio button')
genre = st.radio('오늘의 점심은?', ('국밥', '제육', '돈까스'))
if genre == '국밥':
st.write('인정합니다.')
elif genre == '제육':
st.write('개맛있겠다.')
elif genre == '돈까스':
st.write('개좋아.')
배고프다.
라디오...를 요즘 볼 일은 잘 없지만,
나 중학생때는 라디오 청취가 취미인 클래식한 친구들이 종종 있었더랬다. 나라든가
그시절 라디오를 보면 버튼 하나를 눌렀을 때 그 버튼이 눌린 채 고정되어 있다가,
다른 버튼을 누르면 딸-깍 하고 풀리곤 했다.
그래서 하나만 선택가능한 인터페이스를 라디오 버튼이라고 한다.
위 코드를 터미널에서 실행하면,

요런 인터페이스가 생성된다.
# CheckBox
st.header('Checkbox')
agree = st.checkbox('I agree')
if agree:
st.write('good')
else:
st.write('bad')
체크박스는 말 그대로 체크박스다.
주로 Discord처럼 외국 플랫폼에서 많이 접해본 것 같은데,
그 유명한 '로봇이 아닙니다' 옆에 있는 그게 체크박스.


if 문을 활용하여 출력을 조절가능하다.
# SelectBox
st.header('Select box')
option = st.selectbox(
'어떻게 연락 드릴까요?',['Email', 'Mobile phone', 'Office phone']
)
st.write('네 ', option, ' 잘 알겠습니다')
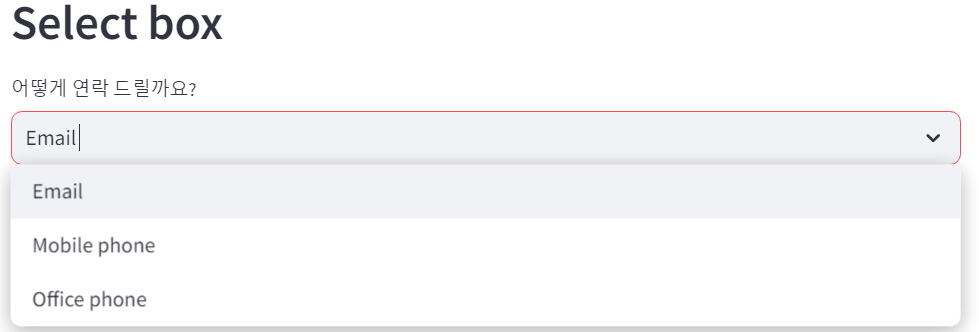
긴 설명이 필요 없다. 이게 바로 셀렉트박스다.
흔히 드롭다운 메뉴라고 하지 않나 싶은데, streamlit에서는 아닌가 보다.
- 슬라이더
슬라이더 구문 자체는 간단하다.
st.header('10. Slider')
st.subheader('**_Slider- 이전 구간_**')
age = st.slider('나이가 어떻게 되세요?',
0, 130, 30) # 입력허용구간 쌍, 최초 세팅
st.write('I am ', age, 'years old')
st.subheader('**_최소-최대값 내에서 숫자 사이 구간_**')
values = st.slider('값 구간을 선택하세요.',
0.0, 100.0, (25.0, 75.0))
st.write('values: ',values)
변수에 넣는 것으로 생성, 안내문과 허용구간 설정.
최촛값 세팅. 안하면 0으로 세팅된다.
이때 최촛값을 튜플이나 리스트로 주면 버튼 두개짜리 슬라이더가 된다.
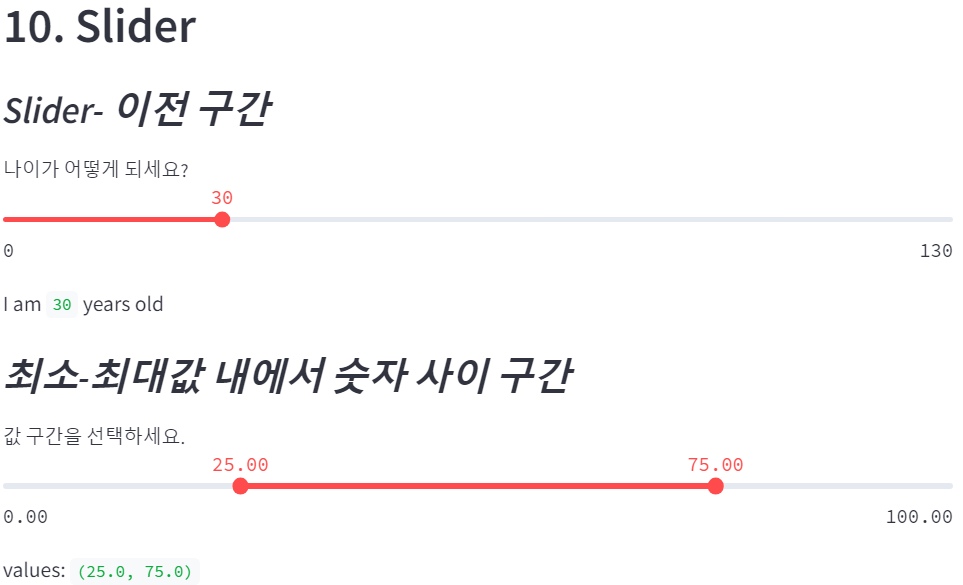
출력도 직관적인 것이 참 좋다.
하지만 데이터 분석가의 입장에서, 이녀석의 진가는 데이터프레임 접근성에 있다.
과정이 기니까 나눠서 보자.
# datetime을 slider에서 활용
st.subheader('**_년 월 일 사이 구간_**')
slider_date = st.slider(
'날짜 구간을 선택하세요 ',
min_value=datetime(2022, 1, 1), # 날짜 전체 구간 : 2021.1.1~2021.12.31
max_value=datetime(2022, 12, 31),
value=(datetime(2022, 6, 1), # 초기 설정 구간 : 2021.6.1~2021.7.31
datetime(2022, 7, 31)),
format='YY/MM/DD') # 날짜 형식: YY/MM/DD
# slider_date의 구간 날짜 확인하기
st.write('slider date: ', slider_date)
st.write('slider_date[0]: ', slider_date[0], 'slider_date[1]: ', slider_date[1] )
이 방식도 슬라이더의 매개변수 자체는 같다.
min_value나 max_value는 적지 않고 위치 인수로 주어도 된다는 뜻.
value 부분도 위에서 본,
'튜플이나 리스트에 넣어서 버튼 두개짜리 슬라이더를 만드는 법'을 쓴 것이다.
그저 3, 100 이러던게 datetime(2022, 1, 1) 이런 식이라 복잡해 보일 뿐이지.
format 정도만 신경써 주면 슬라이더의 매개변수는 별 볼 일 없다는 뜻이다.
주의해야 할 것은 저기에 접근하는 방법.
st.slider 객체는 튜플을 반환한다.
고로, 인덱싱이 가능하다.
위 코드에서 튜플의 각 요소를 호출하고 있으니, 결과를 보자.
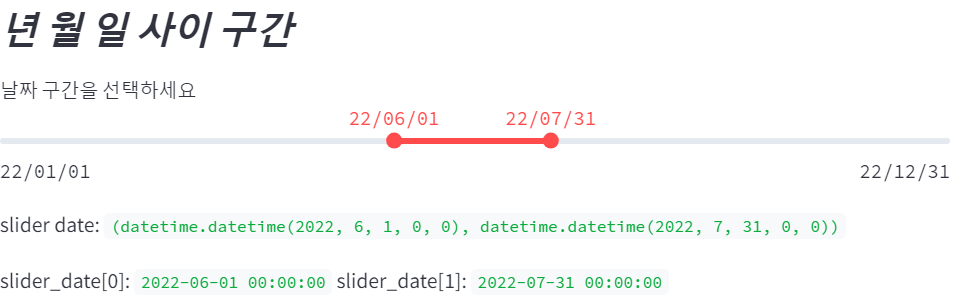
인덱싱 결과물이 현재 선택된 슬라이더의 양 끝 위치를 가리킨다.
즉, 사용자가 드래그를 하는 것으로 인덱싱, 슬라이싱이 가능하다.
데이터프레임 + 인덱싱...?
그렇다. st.slider를 사용해서 보면 드래그만으로 loc을 자유자재로 쓸 수 있다.
그럼 이제부터 데이터프레임을 자유자재로 호출하는 슬라이더를 만들어 보자.
(1) 데이터 불러오기
# st.header('날짜 구간으로 데이터 조회하기')
# 데이터 불러오기
df = pd.read_csv('data_subway_in_seoul.csv', encoding='cp949')
# 날짜 필드의 데이터 형식 확인하기
st.write('날짜 필드 형식: ', df['날짜'].dtypes)
# 데이터프레임 내용 확인하기
st.write(df)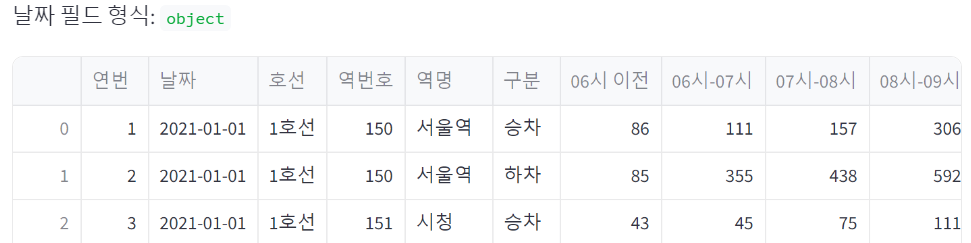
뭐... 이번 미프에서 쓴 joblib같은 걸 활용하면 괜찮겠지만,
위 코드처럼 csv 파일인 경우에는 datetime을 지원하지 않는다.
그러니 object 타입인 '날짜' 컬럼을 우선 datetime으로 바꿔 준다.
(2) (필요할 경우) 날짜를 datetime으로 변경
# 날짜 컬럼을 string에서 datetime으로 변환하기
df['날짜'] = pd.to_datetime(df['날짜'], format='%Y-%m-%d')
# 날짜 필드의 데이터 형식 확인하기
st.write('날짜 필드 형식: ', df['날짜'].dtypes)
# 데이터프레임 내용 확인하기
st.write(df)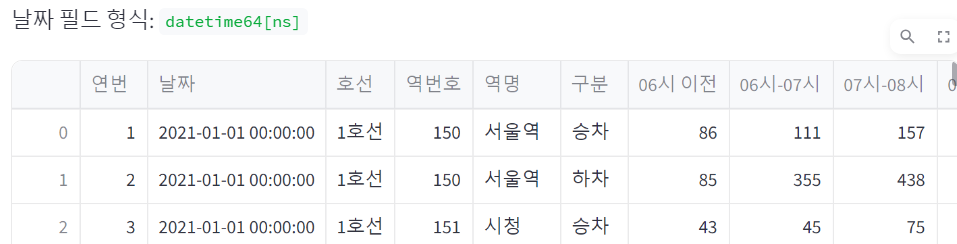
자, pd.to_datetime()으로 무사히 바뀌었다.
(3) 슬라이더 생성해 데이터프레임과 연결
# slider를 사용하여 날짜 구간 설정하기
slider_date = st.slider(
'날짜 구간을 선택하세요 ',
datetime(2021, 1, 1), # 날짜 전체 구간 : 2021.1.1~2021.12.31
datetime(2021, 12, 31),
(datetime(2022, 6, 1), # 초기 설정 구간 : 2021.6.1~2021.7.31
datetime(2022, 7, 31)),
format='YY/MM/DD') # 날짜 형식: YY/MM/DD
# slider_date의 구간 날짜 확인하기
st.write('slider_date[0]: ', slider_date[0], 'slider_date[1]: ', slider_date[1])
# slider_date의 선택된 시작, 종료 날짜를 start_date, end_date에 저장하기
start_date = slider_date[0]
end_date = slider_date[1]
# slider 날짜 구간으로 df를 읽어서 새 sel_df 으로 저장하고 확인하기
sel_df = df.loc[df['날짜'].between(start_date, end_date)]
st.write(sel_df)
이제 가장 중요한 것, 저 위의 예처럼 datetime을 사용하는 슬라이더 생성.
이후에 그 슬라이더가 반환하는 튜플(슬라이더로 선택된 양 끝)을 변수에 넣어 준다.
마지막으로 사용자가 볼 데이터프레임을 정의한다.
원본 데이터프레임 기준, 위의 두 변수 사이에 해당하는 구간(df[col].between(A, B))을 선언해 주면 된다.
그리고 출력만 하면 끝.
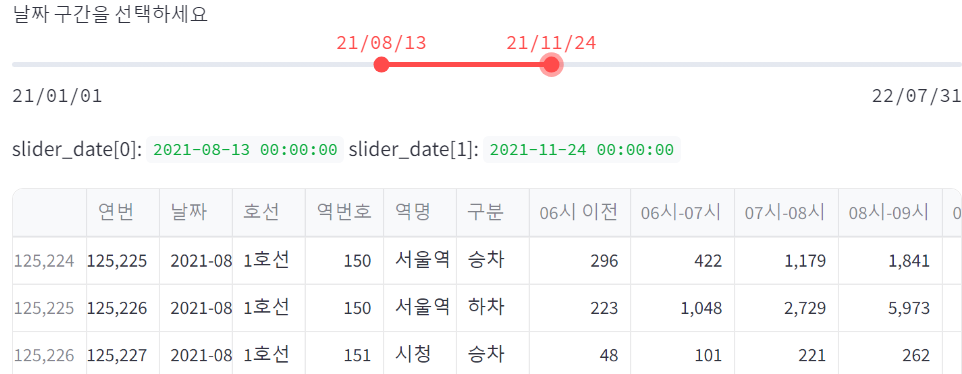
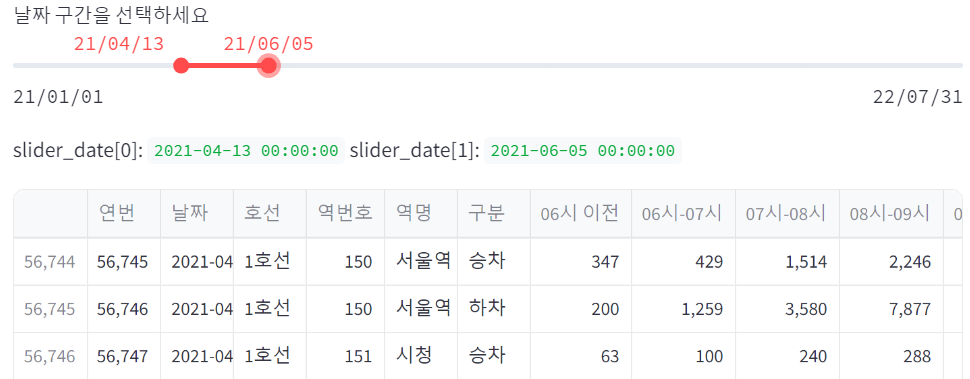
이렇게 슬라이더로 선택한 범위가 달라질때마다 원본 데이터프레임에서 해당 부분을 검색해서 출력한다.
새벽 두시.
TIL 시작한 이래 처음으로 하루만에 정리를 다 못 끝냈다(...)
뭐, 이번에는 신경쓰이는 부분이 많아 이것저것 해 보느라 시간이 간 것도 있으니,
내일 할 것도 많기야 하겠지만.... 일단 자고 나머진 내일 아침에 해 보자.
사상최초 분할 TIL.
Today I Learn. 그런데 이제 Yesterday인