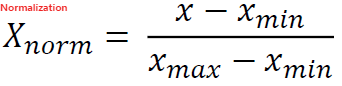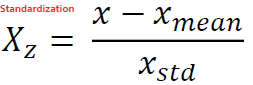sklearn.preprocessing에서 스케일러 모델을 import 해서 사용하면 된다.
# 모듈 불러오기
from sklearn.preprocessing import MinMaxScaler
# 정규화
scaler = MinMaxScaler()
x_train = scaler.fit_transform(x_train) # fit = 학습 데이터의 최솟값, 최댓값 찾는 과정,
# transform : 정규화 적용하기
x_test = scaler.transform(x_test) # 지금 scaler는 x_train의 최댓값, 최솟값을 배운 상태
이렇게 MinMaxScaler를 쓰면 정규화를 할 수 있다.
아까도 말했듯 주의할 점. test데이터도 train데이터를 기준으로 스케일링을 한다.
따라서 x_train에는 fit_transform()을,
x_test에는 transform을 쓴다.
표준화도 같은 방법으로 가능한데,
StandardScaler를 쓰면 된다.
# 모듈 불러오기
from sklearn.preprocessing import StandardScaler
# 정규화
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train) # fit = 학습 데이터의 최솟값, 최댓값 찾는 과정,
# transform : 정규화 적용하기
x_test = scaler.transform(x_test) # 지금 scaler는 x_train의 최댓값, 최솟값을 배운 상태
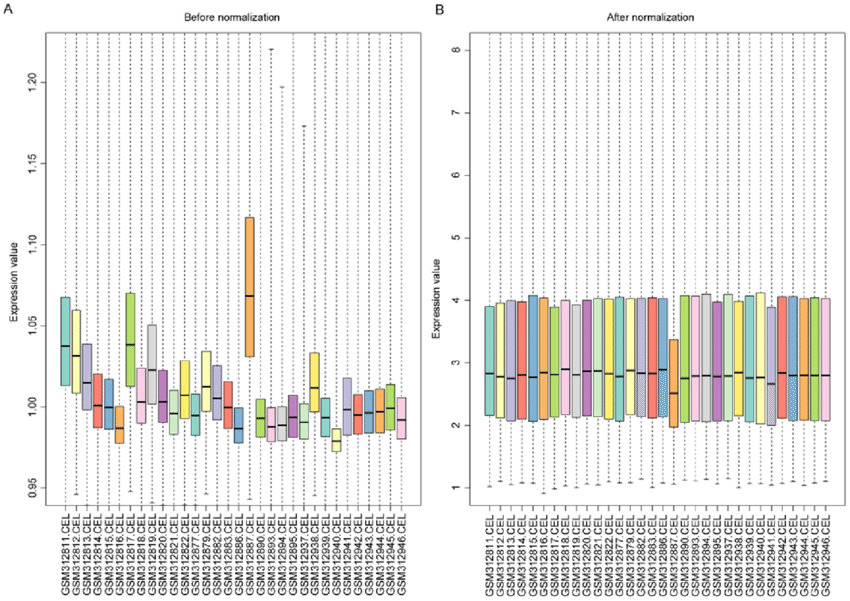
이런 과정을 거쳐 스케일링이 된 자료를 시각화해 보자.
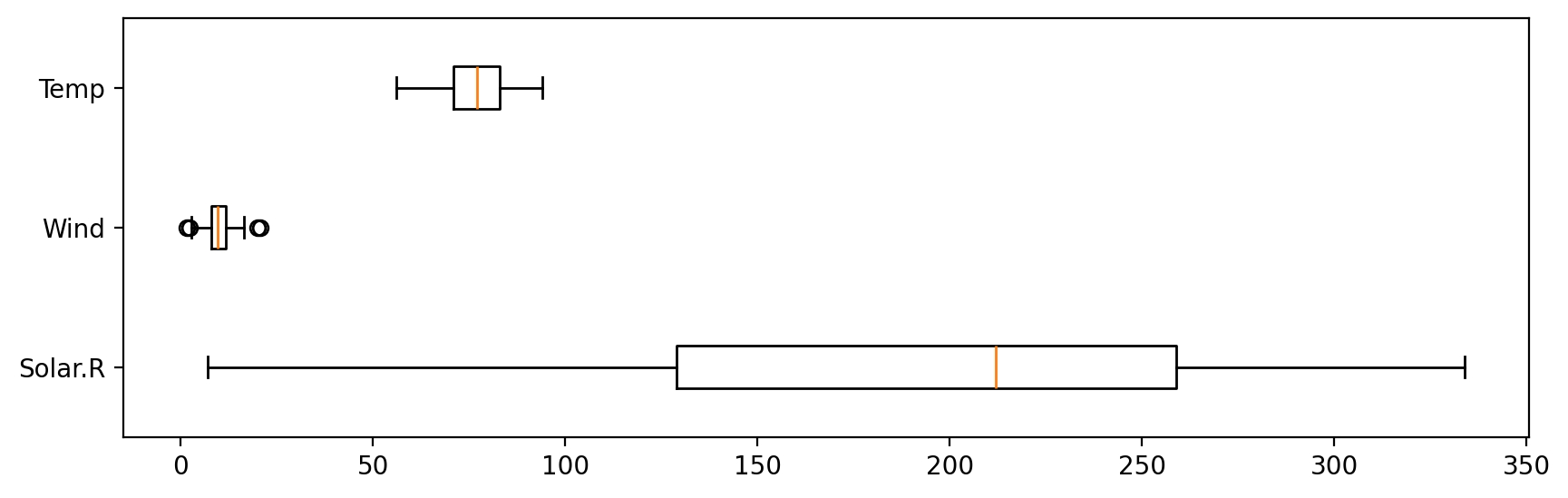
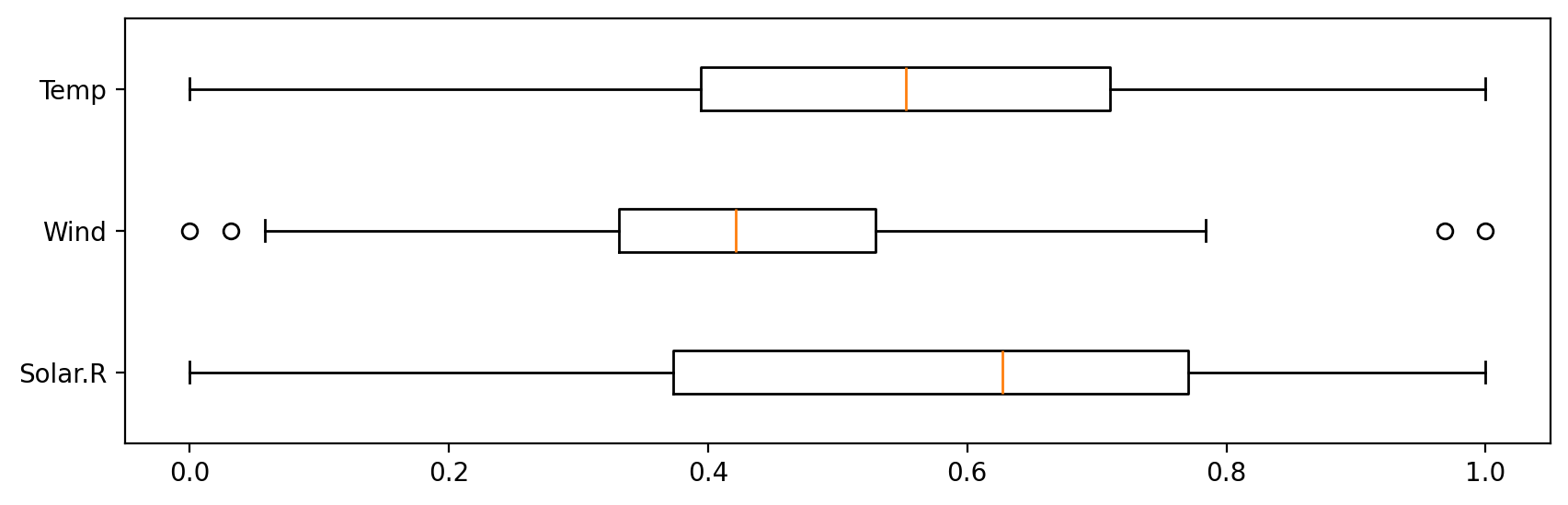
<정규화 결과(MinMaxScaler)>
정규화한 결과, 각 컬럼의 최댓값 - 최솟값이 1 - 0으로 설정되며 각 컬럼의 거리 영향력이 같아졌다.
여기서 Wind 컬럼을 보면, 이상치가 최댓값, 최솟값으로 설정되는 바람에
이상치를 제외한 일반적인 값들은 실질적으로 1과 0이 아닌 값들이 최댓값-최솟값이 되었다.
따라서, MinMaxScaler는 이상치의 영향을 받는다.
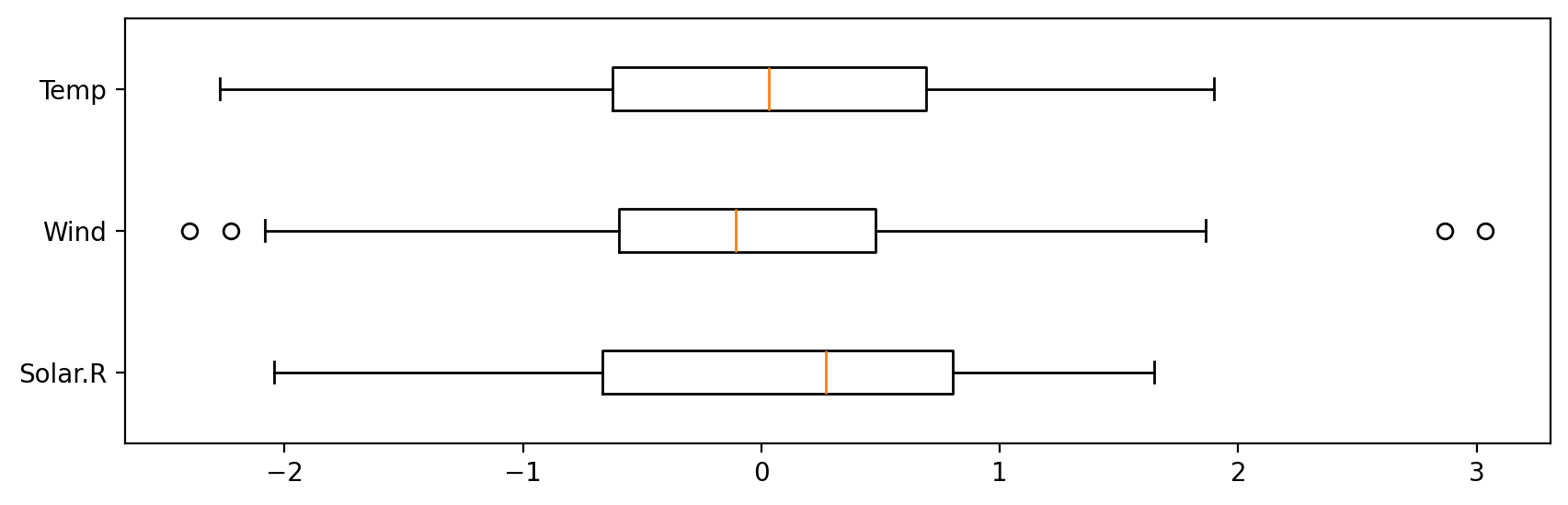
<표준화 결과(StandardScaler)>
반면 StandardScaler는 아래처럼 이상치의 영향 없이 균일한 스케일링이 이루어진다.
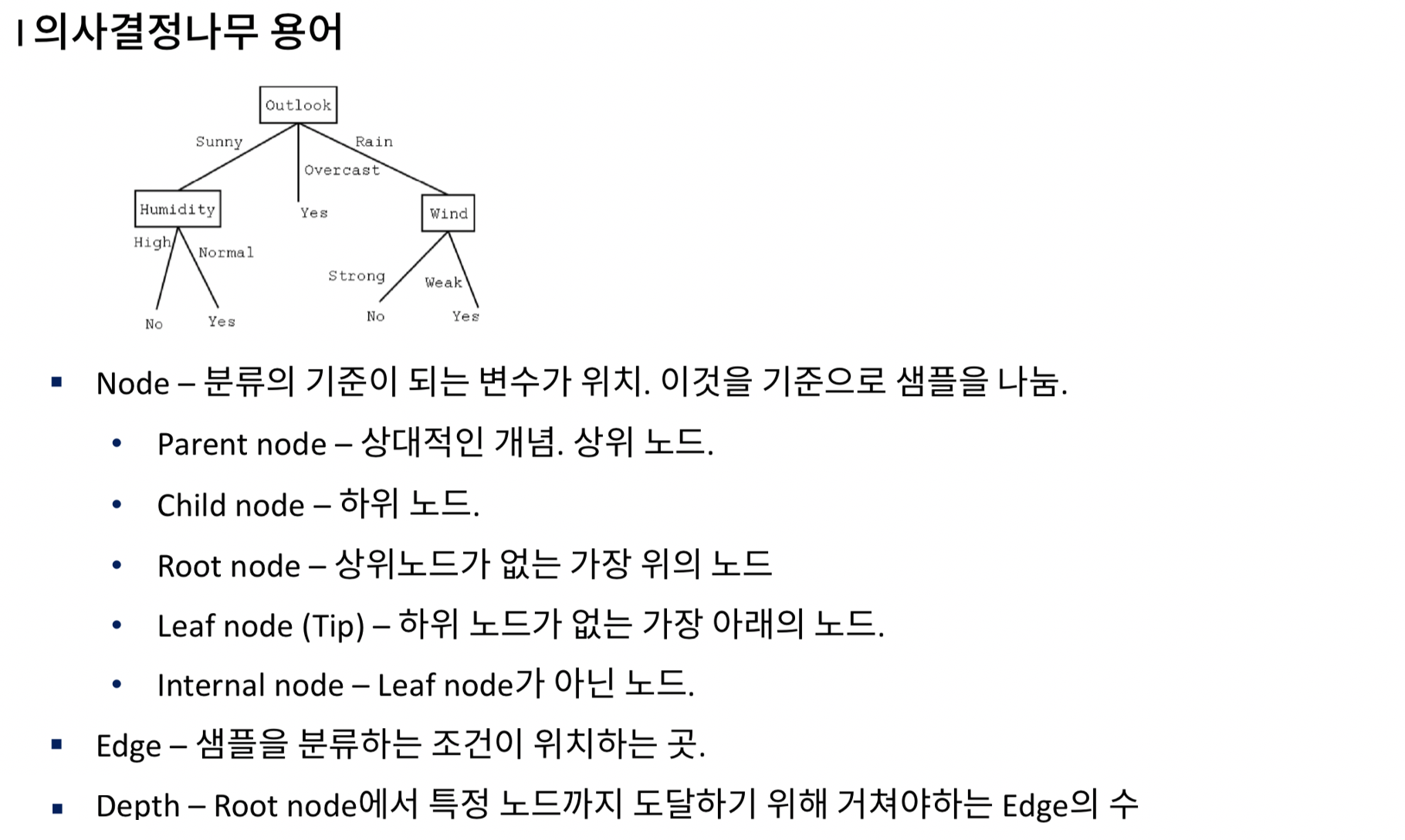
기본 알고리즘(3). Decision Tree
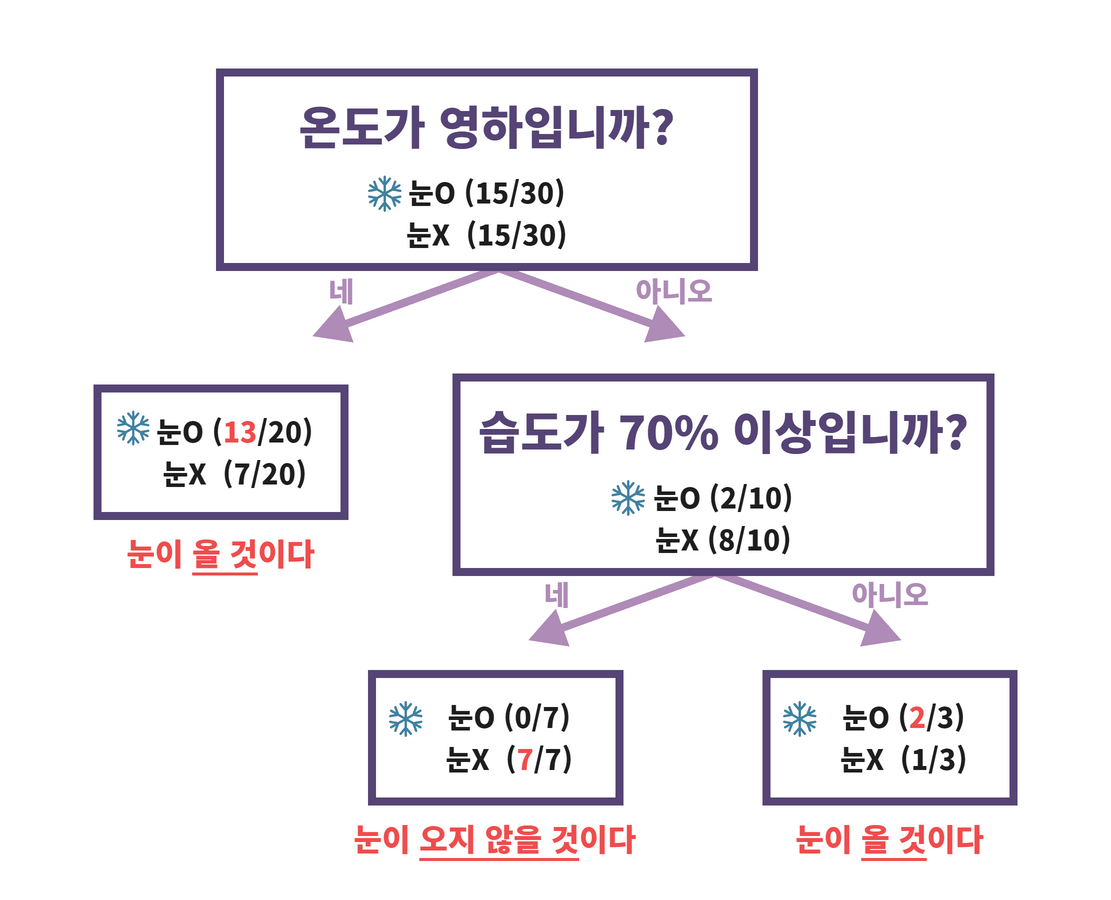
Decision Tree(의사결정나무)는 위처럼 특정 의사결정 규칙을 나무처럼 뻗어나가는 알고리즘이다.
이는 몇가지 특징을 가지고 있는데,
데이터 분석가로서 알아야 하는 가장 중요한 점은 깊이 제한의 필요성이다.
의사결정 나무는 한 계층 내려갈때마다 질문을 하고, 이에 따라 True/False를 구분하며
가지를 쌓아 나간다.
하지만 첫 질문이 모든 분류를 가능케 할 정도로 날카로웠다면?
한 계층만 뻗고도 Decision Tree는 완벽한 답을 내는 것이다.
반면에 질문을 많이 했다면(=깊이가 깊다면) 그만큼 모델이 복잡하다는 것이다.
따라서 의사결정나무가 깊이 진행될수록 과적합의 위험성이 커진다.
따라서 우리는 마치 정원사가 가지를 쳐내듯이
트리가 최대로 뻗어나갈 수 있는 정도(최대 깊이)를 제한해 주어야 한다.
파라미터 'max_depth='를 통해 모델이 최대로 갈 수 있는 깊이를 정할 수 있다.
이를 위해 가장 중요한 것은, 먼저 하는 질문들이 의미있는 것이어야겠지.
<Decision Tree의 다른 특징들> - 스케일링 등 전처리 영향도가 작음 - 분석과정을 관측가능한 화이트박스 모델 - 훈련 데이터에 대한 제약 사항이 거의 없는 유연한 모델
Decision Tree의 용어.
Decision Tree가 뱉어내는 반환값은 어떻게 결정될까?
분류문제의 반환값은 리프 노드 샘플들의 최빈값이고,
회귀문제의 반환값은 리프 노드 샘플들의 평균이다.
그렇다면 성능 평가의 지표는 뭘까?
주로 쓰는 비용함수(평가 지표)는 다음과 같다.
분류문제
불순도
회귀문제
MSE
MSE는 들어 봤지만... 불순도는 처음 듣는다.
아 또 정리해야되네. 흑흑
<불순도> Decision Tree를 활용한 분류 문제가 어떻게 흘러가는지 생각해 보자.
Root 노드에서 질문을 던지면, y_train의 데이터는 둘로 갈라진다. 이때, 당연히 깔끔하게 딱딱 갈라지지는 않겠지. 변수들은 아직 섞여 있을 것이다. 이 '섞인 정도'를 불순도라고 한다.
Decision Tree는 이렇게 층을 늘려 가며 불순도를 차츰 낮춰 간다. 따라서 좋은 질문이란? 불순도를 가장 많이 낮춰 준 질문.
특정 노드의 불순도가 낮다는 것은 해당 노드의 요소들이 특정 클래스에 편중되어있다는 뜻 (= 분류가 잘 됐다는 뜻)
이런 불순도를 수치화할 수 있는 지표로는 두 가지가 있다. 1. 지니 불순도(Gini Impurity)
모델의 기본 불순도 지표는 지니 불순도이다. 지니 불순도는 최솟값으로 0을, 최댓값으로는 '1/클래스의 수'을 갖는다.
예를 들어 3개의 클래스가 0.33씩 나뉘어 있다면? 가장 불순하다는 뜻이지.
2. 엔트로피(Entrophy)
엔트로피도 지니 불순도처럼 혼합된 정도를 나타내는 지표다. 엔트로피는 0~1 사이의 값을 가진다.
데이터 수에 따라서 변동되는 수치가 아니라 순수하게 불순도만을 수치화한 것이므로, 정보 이득 개념을 다룰 때는 엔트로피를 쓴다.
정보 이득(Information Gain)이란 쉽게 말해 어떤 질문이 엔트로피를 줄여 준 정도를 뜻한다.
따라서 정보 이득이 높다는 것은 효과적인 질문, 즉 target의 변별에 중대한 역할을 하는 질문이라는 뜻이다.
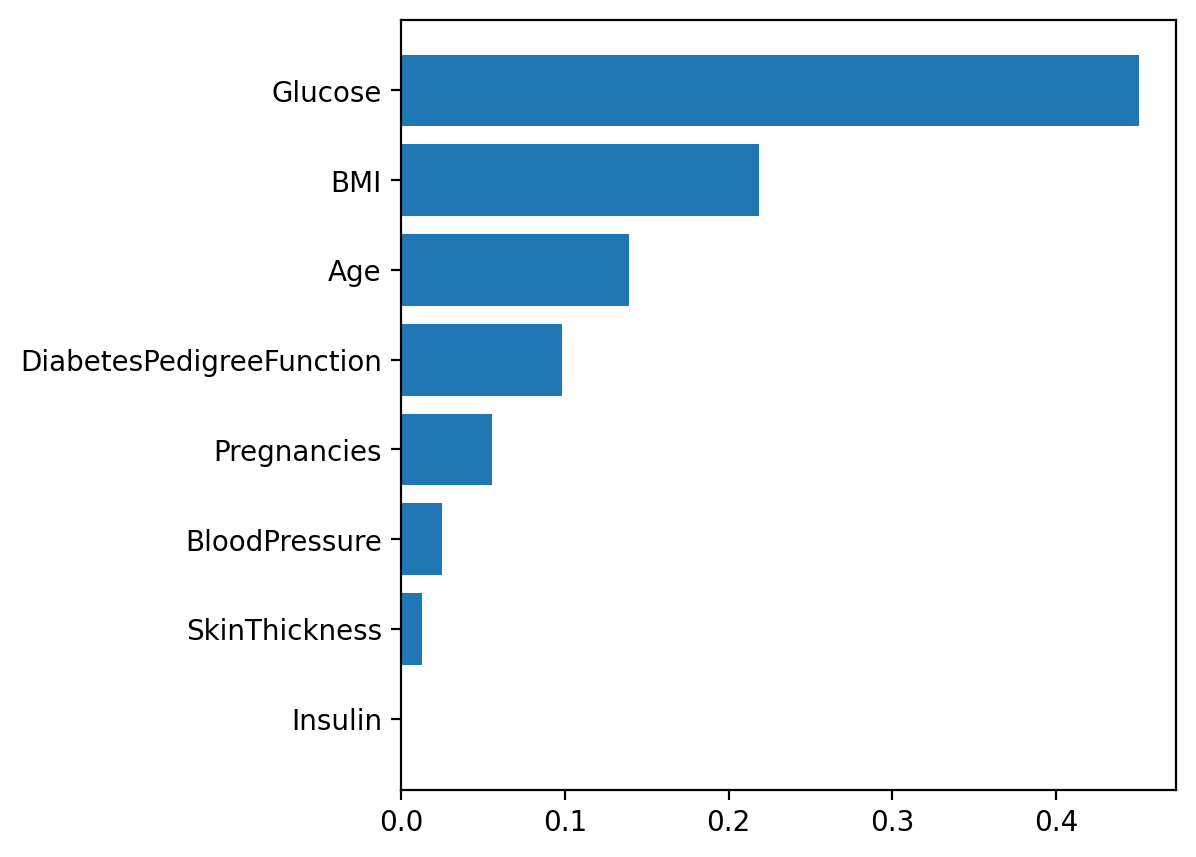
질문이란 것은 결국 '특정 feature에 속하는지 아닌지'의 형태이므로, Decision Tree는 feature의 중요도를 정보 이득이라는 지표로 라벨링하는 것과 같다.
이런 이유로 Decision Tree를 이용한 분석에서는 두 가지를 추가로 표현해 줄 수 있다.
# 트리 시각화
# 시각화 모듈 불러오기
from sklearn.tree import export_graphviz
from IPython.display import Image
# 이미지 파일 만들기
export_graphviz(model, # 모델 이름
out_file='tree.dot', # 파일 이름
feature_names=list(x), # Feature 이름
class_names=['no', 'yes'], # Target Class 이름
rounded=True, # 둥근 테두리
precision=2, # 불순도 소숫점 자리수
max_depth=5, # 출력할 트리의 깊이
filled=True) # 박스 내부 채우기
# 파일 변환
!dot tree.dot -Tpng -otree.png -Gdpi=300
# 이미지 파일 표시
Image(filename='tree.png')
이런 식을 통해 트리 자체를 출력할 수 있다.
각각의 노드에는 질문, 지니 불순도, 전체 샘플 수, 각 클래스에 해당하는 샘플 수, 판단 결과가 적혀 있다.