Linear Regression에서 보았듯, Regression은 회귀 문제를 푸는 알고리즘이다.
그런데 Logistic Regression(로지스틱회귀)는 분류 문제를 푸는 회귀 모델이라는 독특한 모델이다.
이게 왜 그런가 하니...
위 그림처럼 분류 문제에서 이렇게 선형 경계가 나타날 때가 있다.
선 위면 파란색, 선 아래면 빨간색이다.
그런데 잘 보면, 경계에 가까운 점들은 선 위인데 파란색일 때도 있고 그 반대도 있다.
이런 경우, 우리는 저 경계 부근의 값을 두 가지로 처리할 수 있다.
경계 주변 일정 범위에 있는 값은 이상치로 다 날려 버린다.
경계에서 멀어질수록 100%에 가깝게, 경계에 가까워질수록 50%에 가깝게 표현한다.
1은 이후에 배울 Support Vector Machine의 방식이고,
2가 바로 Logistic Regression의 방식이다.
'경계쪽이면 위에 있어도 파랑 아닐 수도 있음~' 하는거지.
따라서 Logistic Regression에서는 데이터에 대해 두가지 처리를 한다.
Step 1. Linear Regression과 마찬가지로 y = w0 + w1x의 편향(w0)과 가중치(w1)를 구함으로써 적절한 분류 기준을 회귀선의 형태로 나타낸다.
Step 2. 자료를 Sigmoid / Softmax 함수에 통과시켜 1과 0 사이의 확률값으로 만든다.
1단계야 지난 포스팅에 설명되어 있고,
2단계를 살펴보자.
위에서 Logistic Regression은 경계선에서 멀수록 확실한 분류,
가까울수록 불확실한 분류로 본다고 했다.
그런데 기본적으로 회귀선은 직선이고, 직선의 범위는 [-inf : inf]이다.(무한하다)
따라서 우리는 그 직선을 [0:1]로 바꾸어 주어야 한다.
이때 쓰이는 것이 Sigmoid 함수(Softmax는 뒤에서 살펴보자.)이다.
시그모이드 함수 식, -x 대신 -z도 쓴다.확실한 1 아니면 확실한 0이 아닌, Sigmoid 함수의 결과에는 확률 구간이 있다..
시그모이드 함수를 통과한 데이터는 직선이 아닌 s자 곡선 주변에 분포하게 되는데,
임계값 0.5를 기준으로 더 높으면 1일 확률이 높으니 1,
더 낮으면 0일 확률이 높으니 0으로 분류한다.
이것만 보면 그냥 회귀선 위아래로 끊는 것처럼 보일 수도 있지만,
시그모이드 함수를 통해 0~1사이의 값이 되었기에 확률 기반 해석이 가능해진다는 장점이 있다.
0과 1로 분류하기는 하지만, '선에 가까울수록 분류가 틀렸을 확률이 있다'는 정보가 들어 있다.
따라서 코드상으로도 각 row의 분류 결과뿐 아니라,
그 확률도 볼 수 있다.
# 확률값 확인
p = model.predict_proba(x_test)
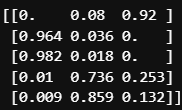
print(p[:10].round(3)) # 왼쪽은 0일 확률, 오른쪽은 1일 확률
첫 10행의 확률표
이를테면 위 확률표의 8번째 행은, 0.578 : 0.422의 확률로 0으로 판결되었다.
이 행의 대상은 회귀선에 가깝다는 뜻이다.
이러한 특징으로 인해, 분석자의 판단에 따라 임계점을 조절해 recall을 올리거나 내릴 수도 있다.
# 새로운 예측값 : 임계값 조정 가능 - 임계값을 낮추면 1을 더 적극적으로 판별
y_pred2 = [1 if x > 0.4 else 0 for x in p1] # if 컴프리헨션 : 0.4로 임계값 조절
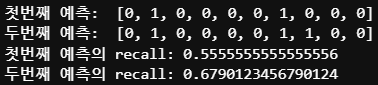
print('첫번째 예측: ',[x for x in y_pred[:10]]) # y_pred2와 포맷을 맞추기 위한 처리
print('두번째 예측: ', y_pred2[:10])
print('첫번째 예측의 recall:', recall_score(y_test, y_pred))
print('두번째 예측의 recall:', recall_score(y_test, y_pred2))
임계값을 0.4로 조정해 8번째 값이 1로 바뀌고, recall도 올랐다.
이 자료는 당뇨병 예측 모델이었는데, 진료 모델의 특성상 recall이 중요하므로
0.4로 낮추는게 적절한 조치였던 것으로 보인다.
Softmax의 경우, n차원으로 바뀌기에 그림으로 나타낼 수는 없지만
마찬가지로 각 범주에 속할 확률로 변환해 주는 함수다.
softmax 함수를 통과한 범주 3개짜리 자료의 확률표.
범주끼리 합하면 1이 된다.
기본 알고리즘(5). SVM(Supprort Vector Machine)
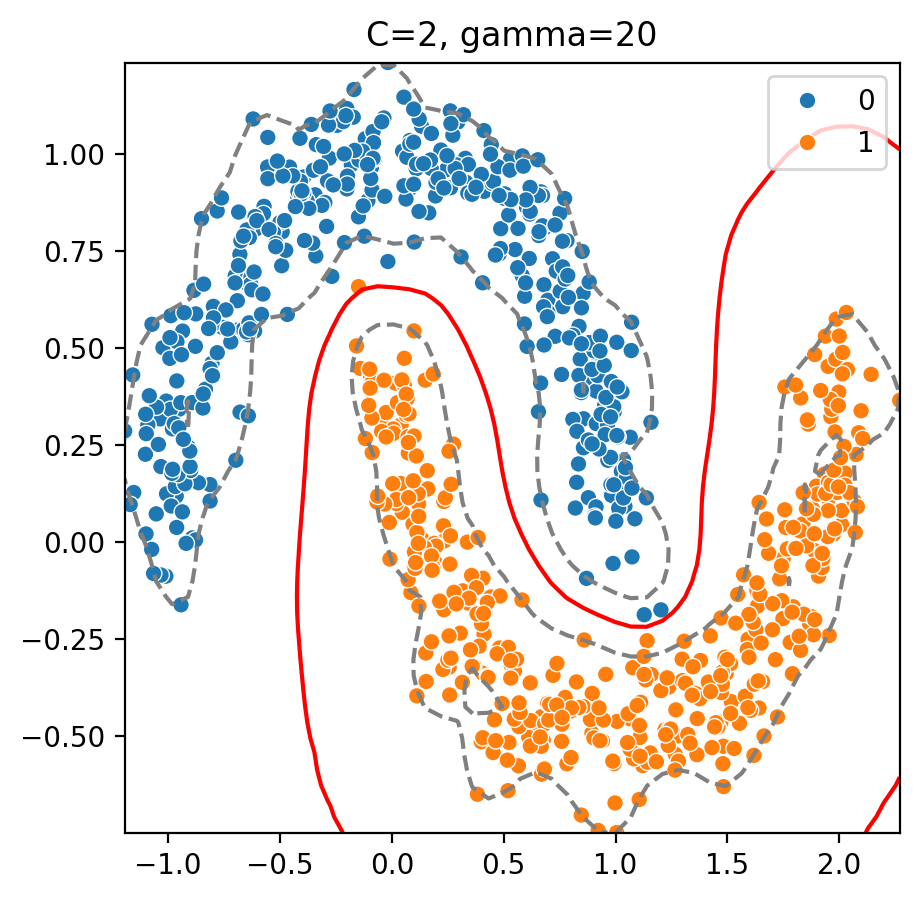
SVM은 자료가 위 그림처럼 나뉠 때, 최선의 결정 경계선을 찾는 알고리즘이다.
이때 각각의 점들이 Vector,
Vector 중에서 결정 경계선을 만드는 결정적 역할을 한 점을 Support Vector라고 한다.
따라서 Support Vector는 결정 경계선이 평행이동할 수 있는 한계점이 되며,
이때 경계선이 평행이동할 수 있는 범위를 Margin이라고 한다.
그렇다면 이 과정에서 Margin 안에 들어온 점이 있다면,
즉 Support Vector 보다 더 결정 경계선에 가까운 점이 있다면
이것들은 이상치로 취급하게 된다.
<Margin 안의 점들을 이상치로 처리하는 이유>
Margin을 좁게 잡는 것, 즉 결정 경계선에 가까운 = 각 범주에 모호하게 속한 점들을 Support Vector로 삼는 것을 '비용(C / Cost)을 높인다'라고 표현한다. 마진이 좁다 = C가 크다 비용이 높아질수록 모델이 데이터에 예민하게 반응한다는 것이고, KNN에서도 봤지만 이것은 모델의 복잡도가 높다(= 과적합의 위험성이 높다)는 것을 의미한다.
<참고사항> SVM은 분류 모델인 SVC와 회귀 모델인 SVR로 나뉘는데, 우리가 일반적으로 접하게 되는 것은 SVC이다.
비선형 데이터의 일종, 선형 모델을 쓰면 과소적합이 발생한다.
헌데, 현실 세계의 데이터란 일반적으로 비선형적인 경우가 더 많다.
이런 비선형 데이터는 데이터의 차원을 높여서 분류가능한데,
실제로 데이터를 옮기는 것은 계산량이 지나치게 많아 사용하기가 힘들다.
따라서 SVC에서는 파라미터를 통한 커널 트릭을 지원한다.
<커널 트릭> 데이터의 차원을 실제로 높이지는 않으면서 높인 것과 같은 효과를 주는 방법. 2차원 데이터를 3차원에서 보면 결정 경계선을 매우 빠르게 찾을 수 있다.