
오늘로 머신러닝 - 지도학습편이 끝났다.
AICE 준비하면서 생긴 여러 의문들을 해결할 수 있었던 것 같다.
기적의 공부법 선암기 후이해
앙상블 알고리즘이란
지금까지 배운 기본 알고리즘들은 과적합에 취약했다.
이는 감당할 수 있는 복잡성에 한계가 있다는 뜻이고,
자연스레 많은 데이터를 사용하기 힘들게 된다.
앙상블 알고리즘(Ensemble)은 그 이름대로,
복잡성에 한계가 있는 알고리즘을 여러 개 사용하여
힘을 합쳐 문제를 해결하는 알고리즘을 총칭하는 말이다.
앙상블 알고리즘은 몇 유형으로 나뉘는데, 그게 뭐냐면
| 보팅(Votiong) | 같은 데이터로 서로 다른 알고리즘을 학습 | |
| 배깅(Bagging) | 서로 다른 데이터로 같은 알고리즘을 학습 | RandomForest |
| 부스팅(Boosting) | 점진적으로 같은 알고리즘을 발전시킴 | XGBoost, LGBM |
| 스태킹(Stacking) | 다른 알고리즘들의 예측 데이터로 본 알고리즘을 학습 |
일단 강의에서는 RandomForest와 XGBoost, LGBM만 배웠다. 다행이다.
보팅(Voting)
보팅은 서로 다른 알고리즘들을 서로 학습시켜, 이들이 투표하게 만드는 것이다.
튜닝이 된 서로 다른 모델들을 학습시켜 각각의 예측값을 바탕으로 가장 타당한 예측값을 산출하는거지.
보팅은 하드 보팅과 소프트 보팅으로 나뉘는데,
하드 보팅은 다수결, 소프트 보팅은 각 모델의 확률값을 평균내어 가장 높은 값을 정하는 것이다.

# Linear Regression
model_lr = LinearRegression()
model_lr.fit(x_train, y_train)
# KNN ### 파이프라인으로 MinMaxScaler와 묶어 씀
model_knn = make_pipeline(MinMaxScaler(), KNeighborsRegressor())
model_knn.fit(x_train, y_train)
# Decision Tree
model_dt = DecisionTreeRegressor(random_state=1)
model_dt.fit(x_train, y_train)
# Random Forest
model_rdf = RandomForestRegressor(random_state=1)
model_rdf.fit(x_train, y_train)
# Light GBM
model_lgb = LGBMRegressor(random_state=1, verbose=-1)
model_lgb.fit(x_train, y_train)
KNN은 데이터 스케일링이 필요한데,
스케일링 데이터를 별개로 선언하는 것이 번거롭기에 파이프라인을 만들어 묶어 쓴다.
파이프라인을 만들려면 make_pipeline을 import해야 한다.
# 예측 결과 수집
pred_dict = {'p1': model_lr.predict(x_test),
'p2': model_knn.predict(x_test),
'p3': model_dt.predict(x_test),
'p4': model_rdf.predict(x_test),
'p5': model_lgb.predict(x_test)}
# 데이터프레임 선언
result = pd.DataFrame(pred_dict)
# 평균 계산
result['mean'] = result.mean(axis=1)
# 확인
result.head(10)

row마다 각 모델들의 예측값이 들어가 있고, 이를 모아 평균낸 열 result가 있다.
이렇게 앙상블 보팅을 손으로 구현해 보았다만...
이 과정을 자동으로 수행해주는 함수 'Voting'이 있다.
역시 Ensemble 패밀리에 속해 있음.
# 보팅 모델 선언
estimators = [('lr', model_lr),
('knn', model_knn),
('dt', model_dt),
('rdf', model_rdf),
('lgb', model_lgb)]
model = VotingRegressor(estimators=estimators)
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
여기서 예측한 y_pred는 ndarray로 반환된다.
이를 위에 나온 성능평가 표에 붙여 보면...
# 평균 계산
result['y_pred'] = y_pred
# 확인
result.head(10)
수동으로 돌린 값(mean)과 같은 것을 볼 수 있다.
배깅(Bagging)
배깅은 Bootstrap Aggregating의 약자로
Bootstrap은 원본에서 랜덤하게 추출하여 원본 사이즈의 샘플을 만드는 것인데,
이때 중복을 허용하기 때문에 샘플은 원본과 사이즈는 같고 내용은 다르다.
(일치율이 63% 정도라고 한다.)
이렇게 여러 개의 샘플을 만들어서, 똑같은 알고리즘에게 각 샘플을 학습시킨다.

배깅의 최대 장점은, 개별 알고리즘들이 서로 다른 부트스트랩 샘플을 학습하기 떄문에
개별 모델의 과적합된 부분을 상쇄할 수 있다.
<과적합 상쇄의 원리>
과적합은 학습데이터에만 너무 특화되는 현상이기에,
서로 학습데이터가 다른 모델들의 교집합에는 포함되지 않는다.
이후 각 과정이 끝나고 나면,
범주는 투표 방식, 연속형은 평균 방식으로 데이터를 집계한다.
이 원리를 사용하는 대표적인 알고리즘이 그 유명한 Random Forest 알고리즘이다.

이녀석은 부트스트랩 데이터들을 여러 Decision Tree에게 학습시킨다.
Decsion Tree는 같은 모델들이지만,
부트스트랩 데이터들이 서로 다르기 때문에 다양한 결과를 내놓으며
과적합은 자연히 상쇄된다.
부스팅(Boosting)
같은 알고리즘으로 모델 여러 개를 만든 후 순차적으로 학습하는 것이다.
이전 모델이 제대로 예측하지 못한 데이터에는
가중치를 부여해서 피드백하고,
그 피드백을 바탕으로 모델이 오차를 줄인다.
이 과정이 반복되면서 점차 성능을 향상시키는 것이다.
성능 측면에선 가장 뛰어나지만, 속도가 느리다.
무엇보다도 '학습 데이터'에 대한 오차를 점점 줄이는 것이기 때문에 과적합 가능성이 있다.
그러나 여전히 강력한 앙상블 알고리즘이기에, 느리다는 점을 제하고 많이 쓰이는
대표적인 알고리즘으로는 XGBoost와 LightGBM이 있다.
이들도 RandomForest 처럼 DecisionTree를 사용한다.
<Gradient Boost>
공통적으로 GB가 보이는데, GB는 Gradient Boost라는 뜻이다.
Gradient Boost는 일반적인 부스팅과 달리, 첫 모델의 '오차'를 두번째 모델이 예측하고,
세번째 모델도 두번째 모델의 오차를 예측하는 방식으로 진행된다.
그런 식으로 예측된 오차를 모두 더하면 첫 오차의 근삿값이므로, 이로써 첫번째 모델을 보정할 수 있는 것.

앞서 말했듯 boost 방식은 기본적으로 느리다.
GBM(Gradient Boosting Model)역시 마찬가지인데,
이를 보완하여 연산 속도를 올린 것이 XGBoost(별개 트리의 병렬 처리를 지원한다.)이고,
그걸 또 보완하여 연산 속도를 올린 것이 LGBM(깊이 우선 탐색 방식을 쓴다)이다.
제자의 제자의 제자

추가적으로 얘넨 특징적인 점이 하나 있는데, 결측치에 대해서도 의미를 부여한다.
데이터를 조작하기 전 단계에서 모델을 선택해야 하는 이유 중 하나일 듯.
<하이퍼파라미터>
Random Forest, XGBoost, LGBM의 하이퍼파라미터는 대체로 Decision Tree와 같다.
n_estimators 만들 트리의 수
기본값은 100max_depth Decision Tree와 같음 min_sample_split Decision Tree와 같음 min_sample_leaf Decision Tree와 같음 max_feature 전체 중 몇 개의 tree를 쓸 것인지. (기본값 : auto)
기본값이 좋아서 크게 신경쓸 필요 없음
스태킹(Stacking)
스태킹이란 서로 다른 알고리즘으로 만든 각각의 모델들을 학습시킨 후,
각 모델의 예측값을 최종 모델의 학습 데이터로 쓰는 방법이다.

현실 모델에서 많이 사용되지는 않지만,
미세하게나마 다른 모델보다 성능이 좋아 대회 등에서 많이 사용된다.
일반적으로 기반 모델은 다양한 기본 모델 + XGBoost를 사용하고,
그 예측값으로 학습할 최종 모델은 RandomForest을 주로 쓴다.
배깅과 부스팅은 tree만 100개씩 쓰는 구조라 손으로 구현할 수 없었지만,
스태킹은 보팅과 마찬가지로 손으로 구현할 수 있다.
# KNN
model_knn = make_pipeline(MinMaxScaler(), KNeighborsClassifier())
model_knn.fit(x_train, y_train)
# Decision Tree
model_dt = DecisionTreeClassifier(random_state=1)
model_dt.fit(x_train, y_train)
# Logistic Regression
model_lr = LogisticRegression()
model_lr.fit(x_train, y_train)
# Light GBM
model_lgb = LGBMClassifier(random_state=1, verbose=-1)
model_lgb.fit(x_train, y_train)
보팅과 마찬가지로 앞부분에서는 각 모델들을 학습시키고,
# 예측 결과 수집
pred_dict = {'p1': cross_val_predict(model_lr, x_train, y_train, cv=5),
'p2': cross_val_predict(model_knn, x_train, y_train, cv=5),
'p3': cross_val_predict(model_dt, x_train, y_train, cv=5),
'p4': cross_val_predict(model_lgb, x_train, y_train, cv=5)}
# 데이터프레임 선언
result = pd.DataFrame(pred_dict)
# 최종 모델 학습
final_model = RandomForestClassifier(random_state=1)
final_model.fit(result, y_train)
그 예측 결과를 최종 모델 RandomForest에 넣는다.
당연히, 이것도 실제로는 손이 아니라 라이브러리를 쓴다. 파이썬 만만세
# 스태킹 모델 선언
estimators = [('lr', model_lr),
('dt', model_dt),
('knn', model_knn),
('lgb', model_lgb)]
model = StackingClassifier(estimators=estimators, final_estimator=RandomForestClassifier(random_state=1))
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
참 쉽다.
재료로 쓰이는 개별 모델을 튜닝시킨 상태로 쓰면 더 좋은 성능을 보일 것이다.
오버샘플링, 언더샘플링
실무의 데이터는 일반적으로 불균형적이다.
이런 경우에 일반적인 방법으로는 성능을 제대로 낼 수가 없다.

위처럼 불균형한 데이터에 대한 모델 학습을 진행해 보자.
# 불러오기
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import *
# 선언하기
model = RandomForestClassifier(max_depth=5, random_state=1)
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
1이 극단적으로 적기 때문에, 모델 입장에서는 굳이 '위험하게' 1을 선택할 필요가 없는 것이다.
그 결과, 30개의 1 중에 하나만을 맞췄다.
그래도 0이 훨씬 많은 데이터기에 주어진 1을 다 틀렸어도 acuuracy는 0.92나 된다.
하지만 우리는 종종 accuracy보다 recall을 택해야 할 때가 있다.
따라서 우리는 임의로 저 데이터의 비율을 맞추어 주기도 한다.
이를 언더샘플링/오버샘플링이라고 한다.

언더샘플링
# 불러오기
from imblearn.under_sampling import RandomUnderSampler
# Under Sampling
under_sample = RandomUnderSampler()
u_x_train, u_y_train = under_sample.fit_resample(x_train, y_train)
# 확인
print('전:', np.bincount(y_train))
print('후:', np.bincount(u_y_train))
샘플링 결과 10:1이던 0과 1의 비가 1:1로 맞춰졌다.
데이터의 분포를 보면, 색상의 비가 1:1일 것을 확인할 수 있다.

이러면 1의 중요도를 필요 이상으로 높게 잡는 문제가 생기지 않을까?
이런 생각이 드는게 정상이다.
실제 데이터도 학습 데이터랑 웬만하면 비슷할 거고,
1은 0의 10% 남짓일 확률이 높다.
하지만 이 방법의 목적은 recall을 높이는 것이다.
샘플링을 거치면 비율이 맞으면서 모델이 target의 중요도를 높게 잡고,
1이라는 판단 자체를 많이 내리게 된다.
당연히 0인데도 1이라고 하는 경우가 늘어나겠지만(= precision이 떨어지겠지만)
쓸만한 recall을 확보할 수 있다.
강사님 표현을 빌리자면 '진짜 환자를 놓칠 일이 줄어드는' 것이다.

오버샘플링
원리는 같다. 위 데이터에 언더가 아닌 오버를 불러오면
# 불러오기
from imblearn.over_sampling import RandomOverSampler
# Over Sampling
over_sample = RandomOverSampler()
o_x_train, o_y_train = over_sample.fit_resample(x_train, y_train)
# 확인
print('전:', np.bincount(y_train))
print('후:', np.bincount(o_y_train))
이번엔 큰 쪽으로 맞춰졌다.

주황 점들이 많이 추가되었지만 파란 점과 겹쳐져 있으므로 보이지 않는 상태.
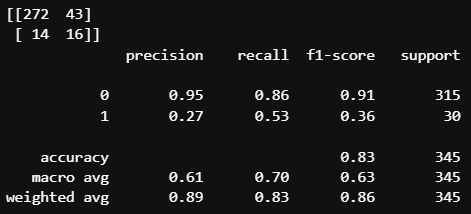
아무래도 기준을 0에 개수로 맞춰서 그런지, 1보다는 0의 recall이 더 좋다.
1의 recall을 볼 일이 더 많다는 걸 고려하면 언더샘플링이 더 유용할 듯싶다.